| 发起:唐里 | 校对:敬爱的勇哥 | 审核:付腾 |
|---|---|---|
| 参与翻译(2)人:路双宁、黄闯 | ||
| 原文:Natural Language Processing: From Basics to using RNN and LSTM | ||
机器机器学习领域最令人着迷的进展之一,是培养机器理解人类交流的能力的进步。机器学习的这一分支被称为自然语言处理。
本文尝试解释自然语言处理的基础知识,以及随着深度学习和神经网络的发展,自然语言处理所取得的快速进展。
在我们深入研究之前,有必要了解一些基础知识。
语言是什么?
一种语言,基本上是一个由人类社会共享的固定的词汇表,用来表达和交流他们的思想。
这个词汇表作为他们成长过程的一部分被世代相传,并且大部分保持不变,每年会增加很少的部分作为补充。
诸如词典之类的精细资源得到了维护,以便一个人遇到一个新词时,他或她可以通过参考词典来了解其含义。一旦人们接触到这个词,它就会被添加到他或她自己的词汇表中,可以用于进一步的交流。
计算机如何理解语言?
计算机是在数学规则下工作的机器。它对人类可以轻松做到的事缺乏复杂的解释和理解,但它能在几秒内执行完复杂的计算。
计算机要处理任何概念,都必须有一种方法以数学模型的形式表达这些概念。
这种约束极大地限制了计算机可以使用的自然语言的范围和领域。目前,机器在执行分类和翻译的任务方面非常成功。
分类基本上是将一段文本分类为一个类别,而翻译则是将这段文本转换成任何其他语言。
什么是自然语言处理?
自然语言处理,简称为NLP,被广泛地定义为通过软件对自然语言(如语音和文本)的自动操作。
自然语言处理的研究已经有50多年的历史了,并且随着计算机的兴起而从语言学领域发展起来。
基本转换
正如前文所述,让一台机器理解自然语言(人类使用的语言),需要将语言转换成某种可以建模的数学框架。下面提到的是帮助我们实现这一目标的一些最常用的技术。
分词是将文本分解成单词的过程。分词可以在任何字符上发生,但最常见的分词方法是在空格上进行切分。
词干提取是一种截断词尾以获得基本单词的粗糙方法,通常包括去掉派生词缀。派生词是指一个词由另一个词形成(派生)的词。派生词通常与原始词属于不同的词类。最常见算法是Porter算法。
词形还原对词进行词汇和形态分析,通常只是为了消除词尾变化。词尾变化是一组字母加在单词的末尾以改变其含义。一些词尾变化是单词复数加s,如bat,bats。
由于词干提取是基于一组规则产生的,词干提取返回的词根可能并不总是英语中的一个单词。另一方面,词形还原适当地减少了词尾变化,保证了词根属于英语。
N-grams(N元模型)
N-gram是指将相邻的单词组合在一起来表示目的的过程,其中N表示要组合在一起的单词数量。
例如,考虑一个句子,“自然语言处理对计算机科学至关重要。”
1-gram或unigram模型将句子切分为一个单词组合,因此输出将是“自然、语言、处理、对、计算机、科学、至关重要”。
bigram模型将其切分为两个单词的组合,输出将是“自然语言、语言处理、处理对、对计算机、计算机科学、科学至关重要”
类似地,trigram模型将其分解为“自然语言处理、语言处理对、处理对计算机、对计算机科学、计算机科学至关重要”,而n-gram模型将一个句子切分为n个单词的组合。
将一门自然语言分解成n-gram是保持句子中出现的单词数量的关键,而句子是自然语言处理中使用的传统数学过程的主干。
(参考自然语言处理NLP中的N-gram模型以详细了解N-gram模型及其原理,译者注)
转换方法
在词袋模型表示中实现这一点的最常见方法之一是tf-idf。
TF-IDF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率,译者注)是一种对词汇进行评分的方式,按照它对句子含义的影响的比例为单词提供足够的权重。得分是两个独立评分,词频(tf)和逆文件频率(idf)的乘积。

词频(TF):词频表示词语出现在一篇文章中的频率。
逆文件频率(IDF):衡量词语提供的信息量,即它在所有文档中是常见的还是罕见的。它由计算得出。N是文档总数,d是包含某个词语的文档数。
独热编码
独热编码是另一种以数字形式表示词语的方法。词语向量的长度等于词汇表的长度,每一个句子用一个矩阵来表示,行数等于词汇表的长度,列数等于句子中词语的数量。词汇表中的词语出现在句子中时,词语向量对应位置的值为1,否则为0。

词嵌入
词嵌入是一组语言模型和特征学习技术共有的统称,词汇表中的词语或短语被映射到由实数构成的向量里。这种技术主要用于神经网络中。
(参考什么是文本的词嵌入?以了解更多,译者注)
从概念上讲,它包含将一个词语从一个与词汇表长度相等的维度投射到较低的维度空间,其思想是相似的词语将被投射得更近。
为了便于理解,我们可以将嵌入看作是将每个单词投射到一个特征空间,如下图所示。

然而,事实上这些维度并不那么清楚或便于理解。但由于算法是在维度的数学关系上训练的,因此这不会产生问题。从训练和预测的角度来看,维度所代表的内容对于神经网络来说是没有意义的。
如果你有兴趣对线性代数有一个直观的理解,投影和变换是一些机器学习算法背后的核心数学原理,我将强烈鼓励他们访问3Blue1Brown的“线性代数的本质”。(b站搬运了相关视频,详情请看《线性代数的本质》,译者注)
表示方法
词袋
要使算法获取文本数据之间的关系,需要用清晰的结构化表示。
词袋是一种以表格格式表示数据的方法,其中列表示语料库的总词汇表,每一行表示一篇文本的统计结果。单元格(行和列的交集)表示该特定文本中的列所代表的单词数。
它有助于机器用易于理解的矩阵范式理解句子,从而使各种线性代数运算和其他算法能够应用到数据上,构建预测模型。
下面是医学期刊文章样本的词袋模型示例
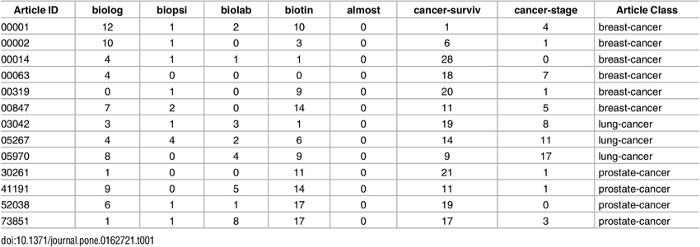
这种表示非常有效,并且负责为一些最常用的机器学习任务(如垃圾邮件检测,情感分类器等)生成模型。
但是,这种表示方法有两个主要的缺点:
-
它忽视了文本的顺序/语法,从而失去了单词的上下文。
-
这种表示方法生成的矩阵非常稀疏,并且更偏向于最常见的单词。试想,算法主要依赖于单词的数量,而在语言中,单词的重要性实际上与出现频率成反比。频率较高的词是更通用的词,如the,is,an,它们不会显着改变句子的含义。 因此,重要的是适当地衡量这些词,以反映它们对句子含义的影响。
嵌入矩阵
嵌入矩阵是表示词汇表中每个单词嵌入的一种方法。行表示单词嵌入空间的维数,列表示词汇表中出现的单词。
为了将样本转换为其嵌入形式,将独热编码形式中的每个单词乘以嵌入矩阵,从而得到样本的词嵌入形式。

需要记住的一件事是,独热编码仅指在词汇表中单词位置处具有值是1的n维向量,n是词汇表的长度。这些独热编码来自词汇表,而不是对一篇文本的统计。
循环神经网络(RNN)
就像它的名字一样,循环神经网络是神经网络非常重要的一种变体,被大量运用于自然语言处理。
循环神经网络的的标准输入是一个词而不是一个完整的样本,这是概念上与标准神经网络的不同之处。这使得网络能够灵活地处理不同长度的句子,而标准神经网络由于其固定的结构无法做到这一点。它还提供了一个额外的优势,可以在文本的不同位置上共享学习到的特征,而这些特征在标准的神经网络中是无法获得的。
RNN将句子中的每个单词都看作在t时刻发生的单独的输入,并使用t-1处的激活值作为t时刻输入之外的输入。下图显示了RNN架构的详细结构。

上述结构也被叫做多对多架构,其中,也就是输入的数量等于输出的数量。这种结构是非常有用的在序列模型中。
除了上面提到的架构外,还有三种常用的RNN架构。
-
多对一的RNN:多对一的架构指的是使用多个输入(Tx)来产生一个输出(Ty)的RNN架构。适用这种架构的例子是分类任务。

上图中,表示激活函数的输出。 -
一对多的RNN:一对多架构指的是RNN基于单个输入值生成一系列输出值的情况。使用这种架构的一个主要示例是音乐生成任务,其中输入是jounre或第一个音符。

-
多对多()架构:该架构指的是读取许多输入以产生许多输出的地方,其中,输入的长度不等于输出的长度。使用这种架构的一个主要例子是机器翻译任务。

Encoder(编码器)指的是读取要翻译的句子的网络一部分,Decoder(解码器)是将句子翻译成所需语言的网络的一部分。成所需语言的网络的一部分。
RNN的局限性
RNN是有效的,但也有一定的局限性,主要在于:
-
上述RNN架构的示例仅能捕获语言的一个方向上的依赖关系。基本上,在自然语言处理的情况下,它假定后面的单词对之前单词的含义没有影响。根据我们的语言经验,我们知道这肯定是不对的。
-
RNN也不能很好地捕捉长期的依赖关系,梯度消失的问题在RNN中再次出现。
这两种局限性导致了新型的RNN架构的产生,下面将对此进行讨论。
内控循环单元(GRU)
它是对基本循环单元的一种修改,有助于捕获长期的依赖关系,也有助于解决消失梯度问题。

GRU增加了一个额外的存储单元,通常称为更新门或重置门。除了通常的具有sigmoid函数和softmax输出的神经单元外,它还包含一个额外的单元,作为激活函数。使用是因为它的输出可以是正的也可以是负的,因此可以用于向上和向下伸缩。然后,该单元的输出与激活输入相结合,以更新内存单元的值。
因此,在每个步骤中,隐藏单元和存储单元的值都会被更新。存储单元中的值在决定传递给下一个单元的激活值时起作用。
详细的解释请参考https://towardsdatascience.com/understanding-gru-networks-2ef37df6c9be
LSTM
在LSTM架构中,有一个更新门和一个忘记门,而不是像在GRU中那样只有一个更新门。

这种架构为存储单元提供了一个选项,可以保留t-1时刻的旧值,并将t时刻向其添加值。
关于LSTM的更详细的解释,请访问http://colah.github.io/posts/2015-08-Understanding-LSTMs/
双向RNN
在上述RNN架构中,仅考虑以前时间戳出现的影响。在NLP中,这意味着它只考虑了当前单词出现之前的单词的影响。但在语言结构中,情况并非如此,因此靠双向RNN来拯救。

双向RNN由前向和后向循环神经网络组成,并结合两个网络在任意给定时间t的结果进行最终预测,如图所示。
在这篇文章中,我试图涵盖自然语言处理领域中流行的的所有相关实践和神经网络架构。对于那些对深入了解神经网络感兴趣的人,我强烈建议你们去Coursera上Andrew Ng的课程。
参考
-
https://machinelearningmastery.com/natural-language-processing/
-
Deep Learning Coursera, Andrew Ng
-
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
-
3Blue1Brown series You Tube
-
https://towardsdatascience.com/understanding-gru-networks-2ef37df6c9be

