Hadoop2.7.5伪分布式配置及遇到的问题总结
发表于 2018-03-04 | 更新于 2024-12-26
| 阅读量:
系统信息
操作系统:Ubuntu 16.04.4 LTS 64bit
Hadoop版本:Hadoop 2.7.5
JDK版本:JDK 1.8.0_161 64bit
参考资料
一、修改配置文件
关于JDK的安装及其环境变量的配置,此处不作赘述。
关于hosts和hostname的说明: /etc/hostname即可。/etc/hosts文件只保留127.0.0.1 localhost,修改完后记得重启电脑使之生效。
在Apache Hadoop官网Release页面 选择好某个版本的binary版,下载,解压至/usr/local/下
这里,我的hadoop目录为/usr/local/hadoop-2.7.5
进入hadoop目录,首先新建文件夹tmp和hdfs,接着,在hdfs里面新建data和name两个文件夹
1 2 mkdir tmp hdfs mkdir -p hdfs/data hdfs/name
进入etc/hadoop目录下,找到以下几个文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml.template、yarn-site.xml。core-site.xml包含了整个Hadoop发行版的通用配置,hdfs-site.xml包含了HDFS的配置,mapred-site.xml.template包含了MapReduce的配置。
该文件默认有个
export JAVA_HOME=${JAVA_HOME}
将其改为你的JAVA_HOME路径,例如
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
2.core-site.xml
修改为如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost</value> <description>HDFS的URI,文件系统://namenode标识:端口号</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-2.7.5/tmp</value> <description>namenode上本地的hadoop临时文件夹</description> </property> </configuration>
3.hdfs-site.xml
修改为如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/local/hadoop-2.7.5/hdfs/name</value> <description>namenode上存储hdfs名字空间元数据 </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/local/hadoop-2.7.5/hdfs/data</value> <description>datanode上数据块的物理存储位置</description> </property> <property> <name>dfs.replication</name> <value>1</value> <description>副本个数,应小于datanode机器数量</description> </property> </configuration>
value的值要以file://开头,否则到后面格式化节点时会出现警告
1 2 3 18/03/04 11:32:16 WARN common.Util: Path /usr/local/hadoop-2.7.5/hdfs/name should be specified as a URI in configuration files. Please update hdfs configuration. 18/03/04 11:32:16 WARN common.Util: Path /usr/local/hadoop-2.7.5/hdfs/name should be specified as a URI in configuration files. Please update hdfs configuration.
4.mapred-site.xml.template
重命名为mapred-site.xml
1 2 3 4 5 6 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
5.yarn-site.xml
修改为如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost</value> </property> </configuration>
更多关于Hadoop的配置,可以参考《Hadoop MapReduce实战手册》中第3章 高级Hadoop MapReduce运维 中的内容。
二、配置环境变量
引入以下变量,用sorce命令或者重启电脑使变量生效
1 2 3 export HADOOP_HOME=/usr/local/hadoop-2.7.5 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
三、配置SSH
我在搭建完Hadoop集群后才发现SSH的配置是如此重要,之前没有详细写,现在补上。
Hadoop集群之间是通过SSH进行通讯的,这就要求主节点和其他节点之间可以通过SSH进行登录,并且要免密登录。对于单机伪分布来说,一台电脑既是主节点,也是数据节点,所以只需要这台电脑开启SSH服务,并能免密登录自己就好。
概括来说,当主机A通过SSH登录主机B时,会在主机A的~/.ssh/目录下生成一个known_hosts文件用来记录主机B的一些信息。实现免密登录,在主机A上使用命令ssh-keygen -t rsa,会在A的~/.ssh/下生成id_rsa和id_rsa.pub,这个id_rsa.pub即是A的公钥,当主机B的~/.ssh/目录下有A的公钥的时候,A就可以免密登录到B。
各位可参考linux实现ssh免密码登录的正确方法
终端执行
1 2 3 4 5 6 7 8 9 apt install ssh #如果没有的话就新建一个,但一定要将.ssh目录的权限设置成700 cd ~/.ssh # 执行下面命令,按四个回车生,成秘钥文件 ssh-keygen -t rsa # 将公钥文件拷贝到目标主机的.ssh目录下,变成authorized_keys,此处目标主机也是localhost ssh-copy-id -i id_rsa.pub user_name@localhost # 登录目标主机 ssh localhost
PS :别闭着眼复制啊喂!记得把user_name改成你自己的用户名啊!!
注意: .ssh目录的权限一定要为700,authorized_keys的权限一定要为600,否则会因权限问题导致无法实现免密登录。
四、尝试启动Hadoop
格式化HDFS文件系统hadoop namenode -format
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. 18/03/04 12:12:22 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = lsn-ubuntu.lan/192.168.199.177 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.5 STARTUP_MSG: build = https://shv@git-wip-us.apache.org/repos/asf/hadoop.git -r 18065c2b6806ed4aa6a3187d77cbe21bb3dba075; compiled by 'kshvachk' on 2017-12-16T01:06Z STARTUP_MSG: java = 1.8.0_161 ************************************************************/ 18/03/04 12:12:22 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] ... ... ... 18/03/04 12:12:23 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop-2.7.5/hdfs/name/current/fsimage.ckpt_0000000000000000000 of size 329 bytes saved in 0 seconds. 18/03/04 12:12:23 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 18/03/04 12:12:23 INFO util.ExitUtil: Exiting with status 0 18/03/04 12:12:23 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at lsn-ubuntu.lan/192.168.199.177 ************************************************************/
进入/usr/local/hadoop-2.7.5/sbin/
依次执行
1 2 ./start-dfs.sh ./start-yarn.sh
查看是否成功的方法,终端输入jps,出现以下信息即成功。
1 2 3 4 5 6 22848 DataNode 23537 NodeManager 23233 ResourceManager 23684 Jps 23046 SecondaryNameNode 22697 NameNode
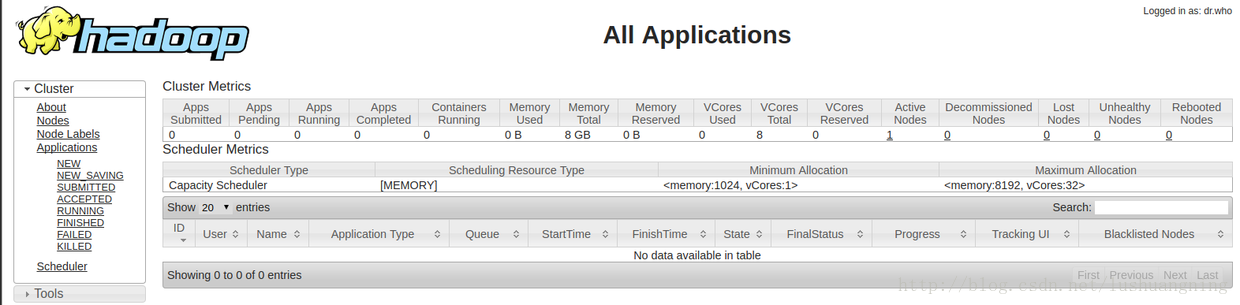
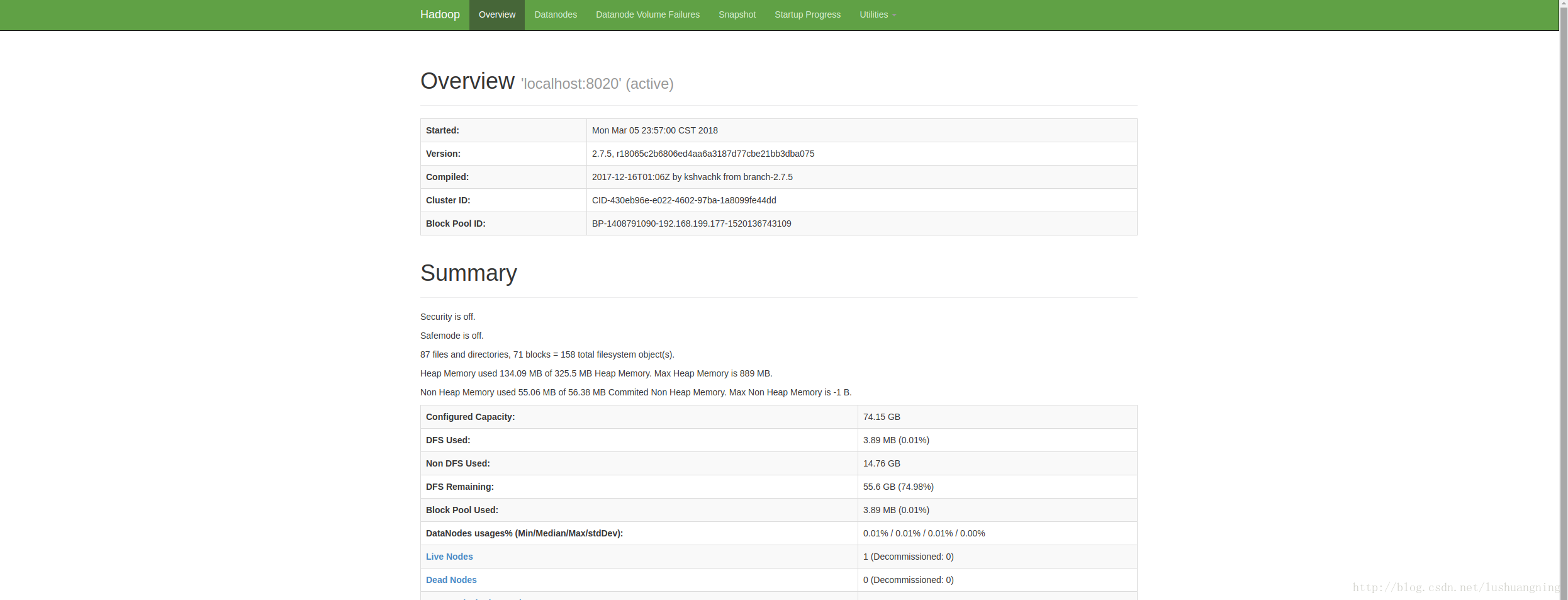
此时,在浏览器分别输入localhost:8088和localhost:50070将会看到以下两个页面。
五、遇到的小问题
1.配置文件中路径不规范
在配置hdfs-site.xml时出现的警告
2.NameNode或DataNode进程未成功启动
Hadoop配置后没有NameNode进程是怎么回事? - 雷雷的回答 - 知乎https://www.zhihu.com/question/31239901/answer/51129753
Hadoop配置后没有NameNode进程是怎么回事? - Ansel Ting的回答 - 知乎https://www.zhihu.com/question/31239901/answer/127300168
DataNode进程未启动-CSD,NASIA_kobe的回答
3.搭建Hadoop集群时未能启动NameNode进程
如果你用腾讯云和阿里云的多个云服务器搭建Hadoop集群,NameNode进程未能启动的话,请参考我另一篇博客,4月份小问题总结 的第4条,这里提供了一种解决思路。其他云服务器也可参考。