开发工具及测试环境配置:
OS Name: Ubuntu 20.04.3 LTS
OS Type: 64-bit
gcc version: 7.5.0
QEMU emulator version: 6.1.0
clang version: 10.0.0-4ubuntu1
Visual Studio: VS2019
缘起
我本来打算跟着田宇的《一个64位操作系统的设计与实现》慢慢写,但是看到第四章就把我劝退了。我这种程度的小白,他竟然试图教会我手写一个 bootloader。就算我能学会怎么实现一个 bootloader,也只是半只脚刚跨过操作系统殿堂的门槛,离操作系统的精髓,进程的管理,内存的分配,分页等等相距甚远,有点本末倒置了。就像你打开PS准备修一张图,在没有整体观的时候进入了细节的误区,总是想着把天空调得更蓝,树木调得更绿。这实际上是非常害人的。
有没有第三方实现的 bootloader,我只需要关注操作系统核心实现的部分就好的项目呢?直到有一天我漫无目的的在 Github 上闲逛,突然这个项目出现在了我的视线中:hurlex-doc,既有分章的代码,又有文档,而且文档是用 latex 编译的。粗略的看了下,作者也是参照了一个外国人的博客和国内的《一个操作系统的实现》写了一个 32 位操作系统的内核,成稿在2014年,距今已有7年,麻雀虽小,五脏俱全,对于学习来说足够了。于是,我从头开始,参照这位作者的文档,一点点的实现一个操作系统的内核。
开发工具安装
Ubuntu 20.04.3 LTS
- 虚拟机 qemu
1 | sudo apt install qemu |
在 Makefile 中已经定义好了内核的编译、链接,镜像的挂载,虚拟机加载,只需执行 make all 即可编译、链接并将镜像加载至虚拟机(想看这个命令执行后发生了什么参见 Makefile 中第 25 行),然后执行 make qemu (对应 Makefile 中第 59 行)即可运行。 lushuangning/MiniOS/chapter3/Makefile
可变形参
原理
关于可变形参
在 CSDN 和博客园里找东西的时候,总给我一种在垃圾堆里刨食的感觉。我对这上面大多数程序员的博客印象都特别差。转载不标明出处,转载投自制,代码排版混乱,抄袭严重,逻辑不严谨。哪一样拎出来都让我这个有着强迫症和精神洁癖的人感到恶心。
这篇博文 C语言中可变参数函数实现原理,是一篇好博文,里面详细讲述了可变形参的实现。
但是我在根据这篇博客写测试代码的时候发现了一个意外的问题。
栈的增长方向及参数的入栈顺序
默认情况下 C 语言的调用约定是 cdecl,参数的入栈顺序是从自右向左,即最右边的参数先入栈在栈底,最左边的参数最后入栈在栈顶。栈的增长方向是从高地址向低地址增长,即栈底的地址最高,栈顶的地址最低。可是当我执行完下面的代码的时候却出现了完全相反的情况:
我使用的平台是 x86-64
1 |
|
输出为:
1 | a = 0x7fff09284c8c |
导致我一时不知道是因为入栈顺序变成从左向右了还是栈的增长方向变了。由于在 VS Code 里我使用的是 clang 进行编译的,严谨起见,我又使用 gcc 编译运行了一遍,结果仍然是
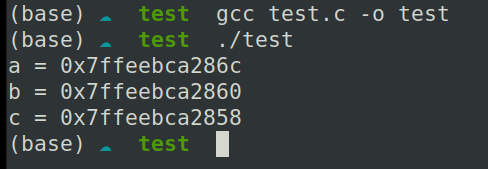
考虑到系统的问题,我在 windows 上做了相同的测试:
在 VS2019 上编译运行的结果如下:
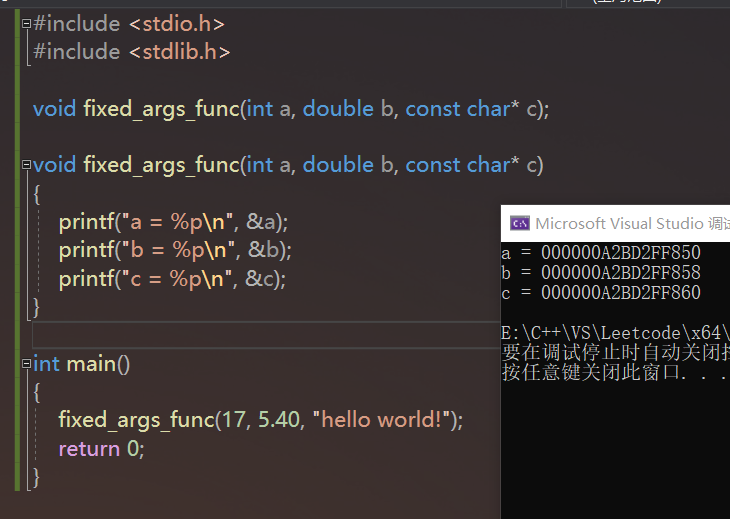
使用 CMake + MinGW 编译运行的结果如下:
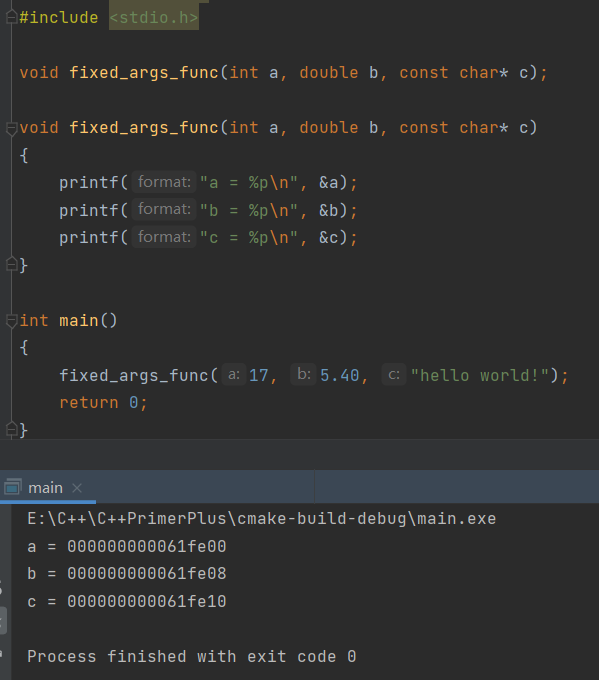
现在很明显了,win10上的运行结果显示参数入栈的顺序是从右往左。那么问题就出在了系统上。
为了查清楚原因,我写了如下代码来确定 ubuntu 下 C 语言栈的增长方向:
1 |
|
输出为:
1 | m1 = 0x7ffc42954300 |
但事实上,一个函数内的栈顺序说明不了这个问题。见问题C语言中,栈的增长方向是向下增,但我测试结果是向上增,正确的方式应该是看函数调用。
1 |
|
输出为:
1 | foo1 i1 = 0x7fff0e59b584 |
可见,地址是变小的,说明栈的增长方向是高地址->低地址。
排除所有的不可能,剩下的结果就是:
在 ubuntu 下使用 gcc 或者 clang 编译 64 位程序,参数的入栈顺序是从左向右的。
到底是不是如此呢?在知乎上看到了这么一个问题:这能说明函数参数入栈顺序是从左到右吗? - 守望的回答
结论:分平台
在 32 位平台上,参数是从右往左入栈的。
在 64 位平台上,对 x86-64 平台来说,寄存器最多可以传递 6 个整型变量。对临时变量使用&的时候,寄存器入栈,但是是按照从左往右的顺序,超过 6 个的参数,他们是连续的,且从右至左入栈。
我们可以写如下的代码进行测试:
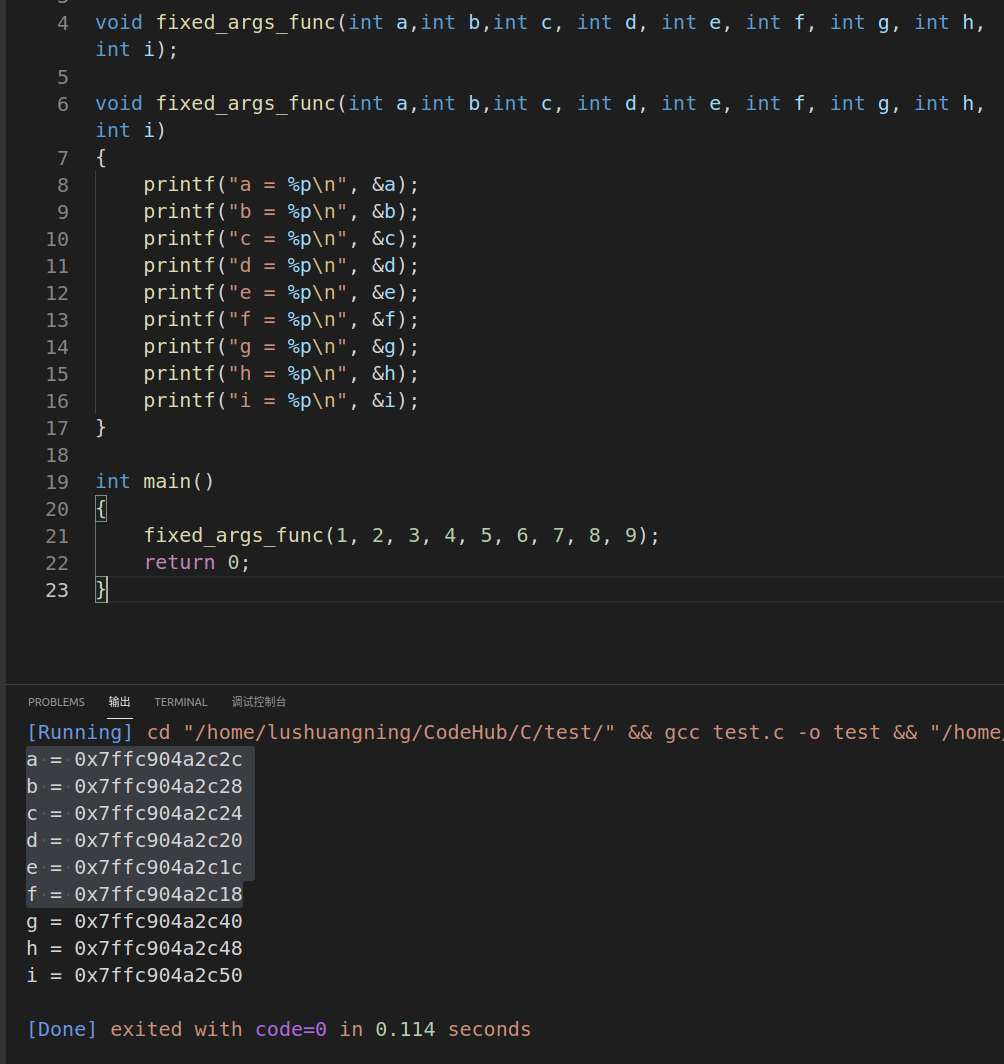
可以看出,前 6 个参数(a~f)的确是按照“从左往右”的顺序入栈的,a 的地址最高,f 的最低。但是从第 7 个参数开始,按照的就是从右往左的顺序入栈了,i 的地址最高,g的地址最低。
但是该测试并不严谨,由于涉及到平台的位数、gcc 和 clang 两个不同的编译器、形参的个数,是整型还是浮点数,不能一一测试。最专业的应该是这个回答这能说明函数参数入栈顺序是从左到右吗? - evilpan的回答 - 知乎。
总结:
这是一个函数调用约定(Calling Convention)问题,不同的调用约定会用不同的方法来传参以及获得返回值。在不同的平台(处理器架构)上,不同的编译器可能使用的调用约定并不相同. 不同的调用约定表格(C/C++编译器)见这里
该问题就此打住,再深究下去对我们的目标来说又成了本末倒置了。我们要实现的是一个 32 位系统的内核,可以姑且认为,函数形参的入栈顺序是从右往左的。
为此,我们将使用命令 gcc test.c -m32 -o test -O0 或者 clang test.c -m32 -o test -O0 来编译 32 位的程序。
内核级屏幕打印函数 printk 的实现
有了可变形参的知识和前面给出的几个宏定义,再结合《linux-0.12内核完全注释v5.0》中第 341 页的代码(赵炯博士的博客见Welcome to OldLinux),我们直接复制了 Linux 早期内核里的一些思想和子函数的实现。
其中 vsprintf 函数见 0.11 内核的第 333 页。
虽然有注释,但是理解起来还是不容易的。可结合 C语言printf函数详解 中 printf 函数来理解。
宏定义
flags(type) 的宏定义,在进行位运算时很方便,flags 在 vsprintf() 函数中默认为 0
1 |
printk 和 printk_color 函数。有了可变形参的认识,这两个函数的代码就容易看懂了,它们本身也较为相似,区别仅仅在于传参时多了两个颜色参数和打印缓冲区内容时调用的打印函数不同而已。顺便一体,buff是一个全局变量,为了节省宝贵的栈资源定义的 static char buff[1024]; // 显示用临时缓冲。
1 | void printk(const char * format, ...) { |
关键指出在于 vsprintf 这个函数的实现。
vsprintf :star:
函数的声明为 static int vsprintf(char *buff, const char *format, va_list args);
变量的定义如下
1 | int len; |
紧接着用一个 for 循环扫描格式字符串,对各个格式转换指示进行相应的处理。这个 for 循环代码较多,为了方便讲述,我先将后面的代码用 ... 作为替代,下面再对每个部分说明。
1 | for(str = buff; *format; ++format){ |
当找到第一个 % 的时候,意味着后面紧挨着的部分是格式指示字符串了,取得格式指示字符串中的标志域,并将标志常量放入flags变量中。
1 | flags = 0; |
取当前参数字段宽度域值放入 field_width 变量中。如果宽度域中是数值则直接取其为宽度值。如果宽度域中是字符 *,表示下一个参数指定宽度。因此调用 va_arg 取宽度值。若此时宽度值小于0,则该负数表示其带有标志域 - 标志(左对齐),因此还需在标志变量中加入该标志,并将字段宽度之取其绝对值。
1 | field_width = -1; |
首先用到了 is_digit() 用于判断是数字还是其它,这是一个宏定义,#define is_digit(c) ((c) >= '0' && (c) <= '9')
然后又用到了 skip_atoi() 函数,该函数将字符数字串转换成整数。输入是数字串指针的指针,返回结果是数值。例如,输入 '123ab' 输出 123,输入 'ab123' 输出 0,输入 '1a23b' 输出 1。
1 | static int skip_atoi(const char **s) { |
接下来是获取格式转换字符串中关于精度的部分。取格式转换串的精度域,并放入 precision 变量中。精度域开始的标志是 . ,其处理过程域和上面宽度域的类似。如果精度域中是数值则直接取其为精度值。如果精度域中是字符 *,表示下一个参数指定精度域。因此调用 va_arg 取其精度值。若此时宽度值小于 0,则字段精度值取 0.
1 | precision = -1; |
接下来分析长度修饰符,并将其存入 qualifer 变量
1 | qualifier = -1; |
最后,分析转换格式指示符,例如我们常用的 d 是表示输出十进制数, c 表示输出字符。
1 | switch(*format){ |
这里面又用到了一个 number() 函数,用于将整数转换为指定进制的字符串。
输入:num-整数;base-进制;size-字符串长度;precision-数字长度(精度);type-类型选项。
输出:数字转换成字符串后指向该字符串末端后面的指针
1 | static char *number(char *str, int num, int base, int size, int precision, |
至此 for 循环结束。
经过上面的 number() 函数,现在的指针 str 指向的是 buff 字符串的末端,我们还需要再添加一个 \0 作为字符串结束的标志,并返回整个字符串的长度。
1 | *str = '\0'; // 最后在转换好的字符串结尾处添上结束符 |
至此,vsprintf() 函数结束。完整的代码可参考 Github - printk.c。
内核调试
使用 qemu 联合 gdb 进行 C 语言源代码级别的调试。
qemu 和 gdb 是两个不同的进程,数据交换必然涉及进程间的通信机制。所幸它们都支持一个标准的调试协议,通过下面的命令即可开启。
1 | qemu -S -s -fda boot.img -boot a |
-s 启动时开启 1234 端口等待 gdb 链接, -S 指启动时不自动运行,等待调试器的执行命令。
这个命令运行之后,gdb 没有内核程序的符号文件,没有办法进行代码级调试,使用下面命令加载待调试内核对应的可执行文件。
1 | file os_kernel |
参考 GDB调试 相关命令。
我已经把这几条命令放到了 scripts/gdbinit 这个文件中,Makefile 文件第 68 行对应的是 gdb 调试的代码。因此我们现在只需要执行 qemu debug 即可开启内核调试(我这里使用的 cgbd,语法与 gdb 并无二致)。

