论文地址:Deep Residual Learning for Image Recognition
自该骨干网络开始,我开始接触到所谓的预训练权重的概念。
以下内容来自深度学习权重初始化
深度学习其本质是优化所有权重的值,使其达到一个最优解的状态,这其中,需要更新权重的层包括卷积层、BN层和FC层等。在最优化中,权重的初始化是得到最优解的重要步骤。如果权重初始化不恰当,则可能会导致模型陷入局部最优解,导致模型预测效果不理想,甚至使损失函数震荡,模型不收敛。而且,使用不同的权重初始化方式,模型最终达到的效果也是很不一样的。因此,掌握权重的初始化方式是炼丹师必备的炼丹术之一。
而预训练初始化是权重初始化的其中一种方式
在实际中,我们大部分是在已有的网络上进行修改,得到预期结果后,再对网络进行裁剪等操作。而预训练模型是别人已经在特定的数据集(如ImageNet)上进行大量迭代训练的,可以认为是比较好的权重初始化。加载预训练模型进行初始化,能使我们进行更高频率的工程迭代,更快得到结果。而且,通常加载预训练模型会得到较好的结果。
但是要注意几个问题:
- 许多文章指出,当源场景与目标场景差异过大时,加载预训练模型可能不是一种很好的方式,会导致领域失配;
- 何凯明在2019年的《Rethinking ImageNet Pre-training》中指出,加载预训练模型并不能使准确率提高,只要迭代步数够多,随机初始化也能产生相同的效果。但实际中,我们无法得知得迭代多少次,模型才饱和;而且迭代步数越多,时间成本也就越大。
总体来说,如果初始版本的模型存在预训练模型的话,我们可以通过加载预训练模型来进行初始化,快速得到结果;然后再根据需求,对初始版本的网络进行修改。
ResNet 要解决什么问题呢?何凯明在论文中说是“解决深层网络的一种退化问题”,并没有直接说缓解梯度消失或梯度爆炸,参考Resnet到底在解决一个什么问题呢? - 知乎 。使用 ResNet 后可以将网络做的更深。另外,论文还提出,在每个卷积层的后面,在 ReLU 激活单元的前面,使用 BN 操作(其实我们已经在前面的博客CNN学习系列:骨干网络学习之VGG中用过该操作了)。
关于 ResNet 的介绍,参看An Overview of ResNet and its Variants
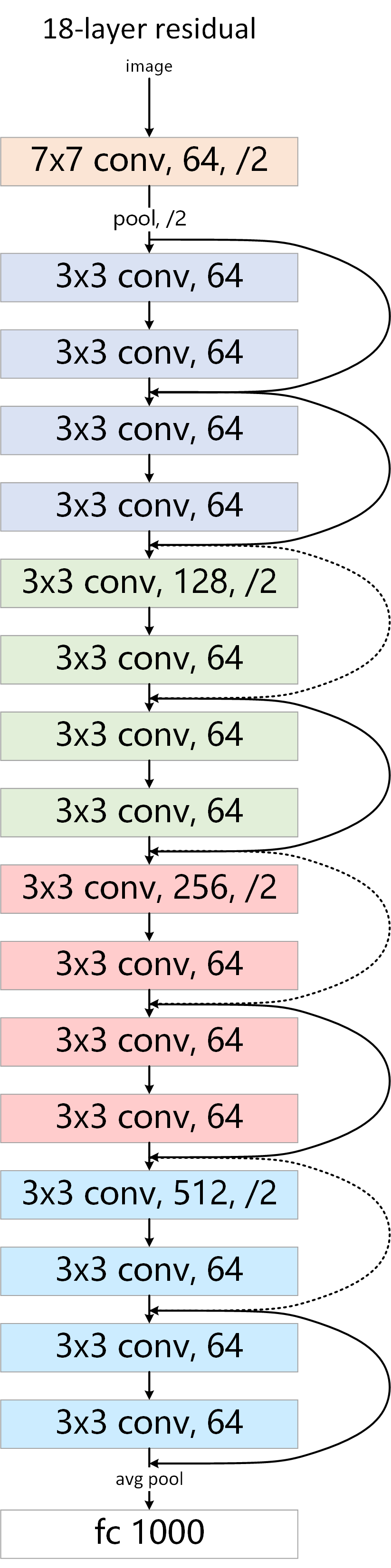
ResNet 的结构:

ResNet 中有两种残差结构,见下图

左边的称为 BasicBlock,它被用于 ResNet-18, ResNet-34 中,右边的叫 BottleNeck,被用于ResNet-50, ResNet-101, ResNet-152 中。
在参考了官方的源码和知乎上的一些介绍之后,完成了下面的代码和分析。
1 | import torch.nn as nn |
在kernel_size为3,stride为1,padding为1的情况下,图像的输出大小和输入大小是一样的。
1 | class BasicBlock(nn.Module): |
注意此处的expansion,为什么要定义这个变量呢?在 BasicBlock 中,各残差块很规整,输出的 channel 都一样

但是在 BottleNeck 中,却出现了一个4倍的关系,如图

另外,我看到这里的时候有个疑惑:1x1的卷积是什么意思?
1 | class BottleNeck(nn.Module): |
为什么要下采样(down_sample)呢?
如果上一个残差块的输出维度和当前的残差块的维度不一样,那就对这个 t 进行 downsample 操作,如果维度一样,直接加就行了,这时直接t += residual,对应到何凯明的论文中的图就是,虚线时候的情况。

1 | class ResNet(nn.Module): |
初始化 ResNet 的时候,经过self.conv1卷积层之后,在kernel_size为7,padding为3的情况下,若stride为1,则输出的图像大小和输入的一样(仍是224),但是此处的stride为2,因此,图像的大小会变为原来的一半,112。对应论文中:
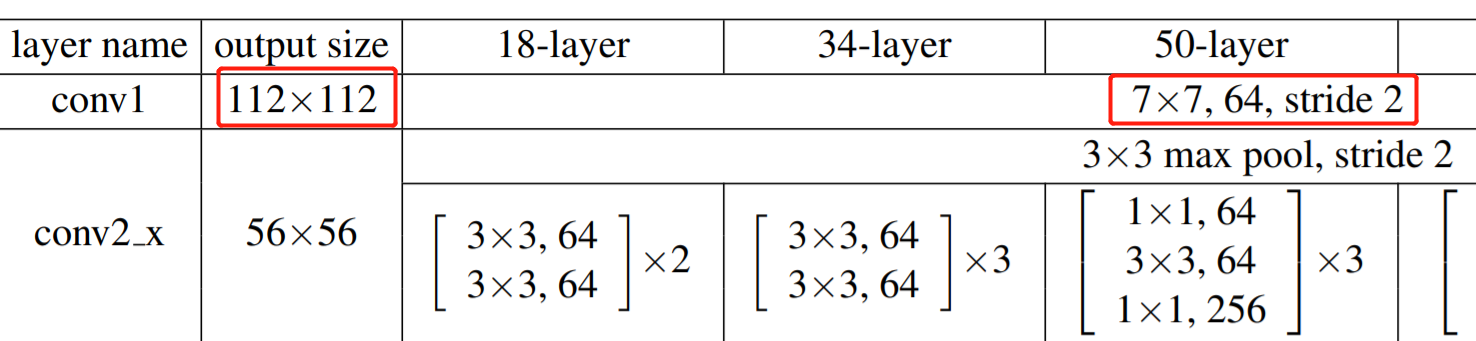
ps: 注意哦,并不是所有stride为2时图像大小都会变为原来的一半,要结合kernel_size和padding等参数一起决定。
另外,在源码中,ResNet类中的for循环下面还有一些代码:
1 | # Zero-initialize the last BN in each residual branch, |
这一改动对性能有0.2%~0.3%的提升,暂且留待后面研究。
1 | def resnet18(pretrained=False): |
最后,查看一下 resnet18 的结构:
1 | resnet18 = resnet18() |
执行结果:
1 | ---------------------------------------------------------------- |
最后,附一张用visio绘制的resnet18的图