除了看王爽的汇编语言程序设计之外,最近还在 b 站上看到了 up 主谭玉刚讲的 Coding Master系列视频,从计算机底层讲起,清晰易懂,包括 x86 汇编,感觉比看书学习效率更快。不过该系列视频使用的是 NASM 汇编器,在语法上与王爽的代码有很多不同之处。
在这之前,补充点计算机启动时候的知识。
内存分配
8086 CPU 是如何分配内存的?
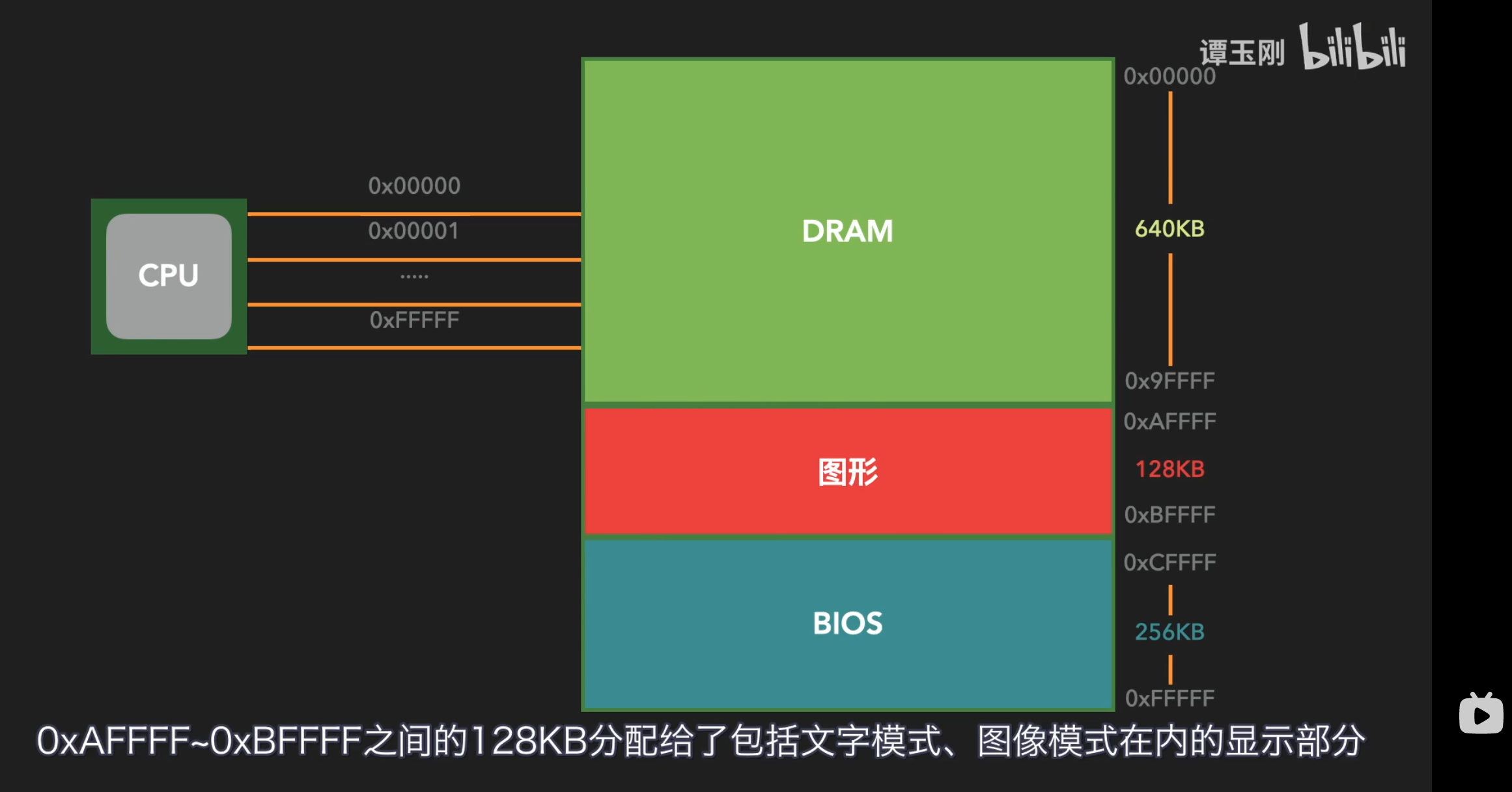
计算机 BIOS 执行完 POST 后,会到硬盘等设备的 MBR 分区上找 BootLoader,找到就加载到内存 0x7c00 的位置。注意这个 0x7c00,刚好等于 32KB - 1024B。这个数字与 IBM PC Model 5150 有关。该计算机支持的最大内存时 32KB,也就是 0x0000~0x7FFF。操作系统起来后,BootLoader 的使命也就完成了,可以将其占用的内存释放。因此,最好的方法是将 BootLoader 放在内存的最后。那么 BootLoader 要占多少空间呢?MBR 扇区要占 512 个字节,栈/数据要占 512 个字节,总共 1KB。将其放在 32KB 的内存空间的最后,BootLoader 的起始位置就是 0x7FFF - 0x0400 + 1 = 0x7C00。后来,计算机内存扩展到了 1MB,数 GB,这个数字也一直没有变。BootLoader的位置也就是从 0x7c00~0x7DFF 的这 512 个字节。
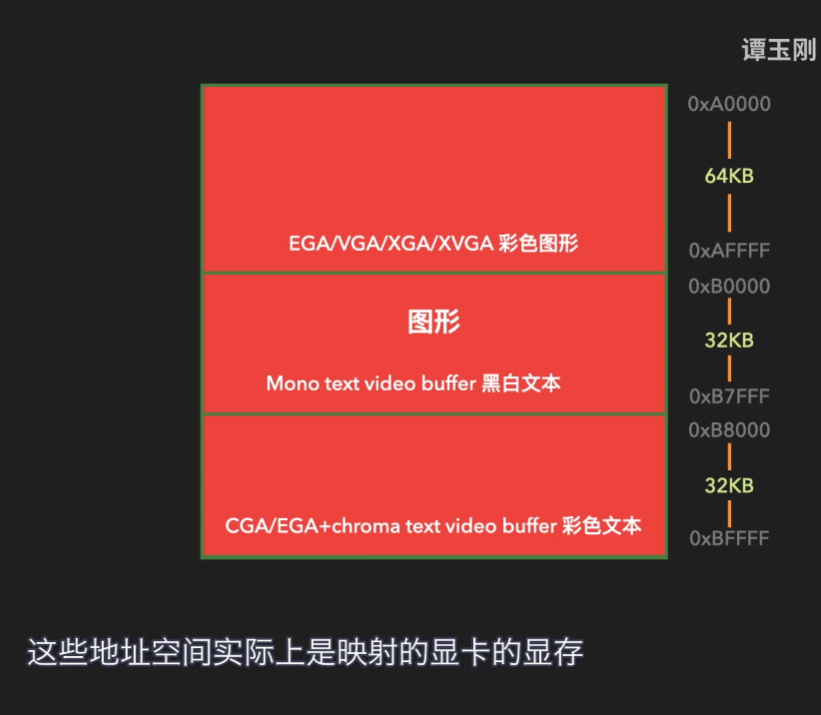
对图形模式的细分:
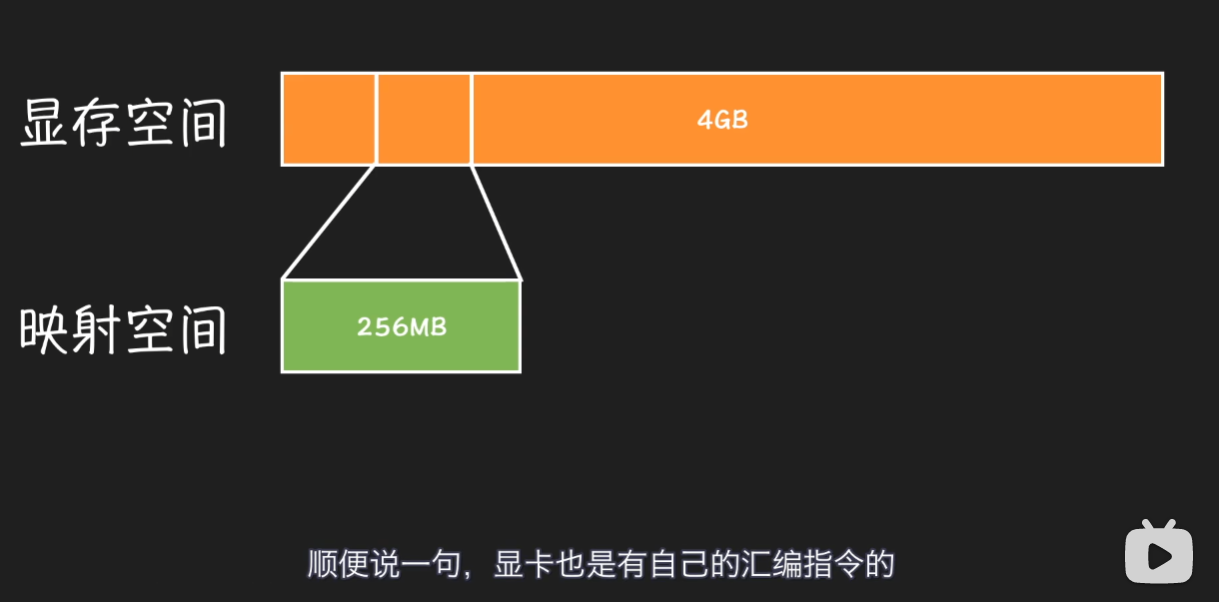
而最新的显卡,显存有十几 GB,但系统只给它分配了几百 MB 的地址空间,不够用怎么办?切换映射到相应地址空间的显存。
内存的寻址方式
- 直接寻址
1 | mov ax, [0x5c0f] |
第一条指令中,源操作数寻址时,处理器将数据段寄存器 DS 中的内容左移4位,加上 0x5c0f,形成20位物理地址。
第二条指令的寻址方式与第一条指令相同。
第三条指令,目的操作数使用了标号和段超越前缀(es:),但它依然属于直接寻址方式。因为标号是数值的等价形式,代表了所在位置的汇编地址。段超越前缀仅仅用来改变默认的数据段。
- 基址寻址
所谓基址寻址,就是在指令的地址部分使用基址寄存器 BX 或者 BP 来提供偏移地址。
1 | mov [bx], dx |
第一条指令执行时,处理器将数据段寄存器 DS 的内容左移4位,加上基址寄存器 BX 中的内容,形成20位物理地址。然后,把寄存器 DX 中的内容传送到该地址所处的字单元里。
使用基址寻址可以使代码变得简洁高效。例如
1 | mov bx,buffer |
基址寻址允许在基址寄存器的基础上使用一个偏移量
1 | xor bx,bx |
- 变址寻址
变址寻址类似于基址寻址,不同之处在于使用的是变址寄存器(又叫索引寄存器)SI 和 DI。
1 | mov [si],dx |
处理器访问由段寄存器 DS 指向的数据段,偏移地址由寄存器 SI 或者 DI 提供。
同样地,编制寻址方式也允许带一个偏移量
1 | mov [si+0x100],al |
- 基址变址寻址
8086 处理器支持一种基址加变址的寻址方式,建成基址变址寻址。
使用基址变址的操作数可以使用一个基址寄存器(BX 或者 BP),外加一个变址寄存器(SI 或者 DI),基本形式为
1 | mov ax,[bx+si] |
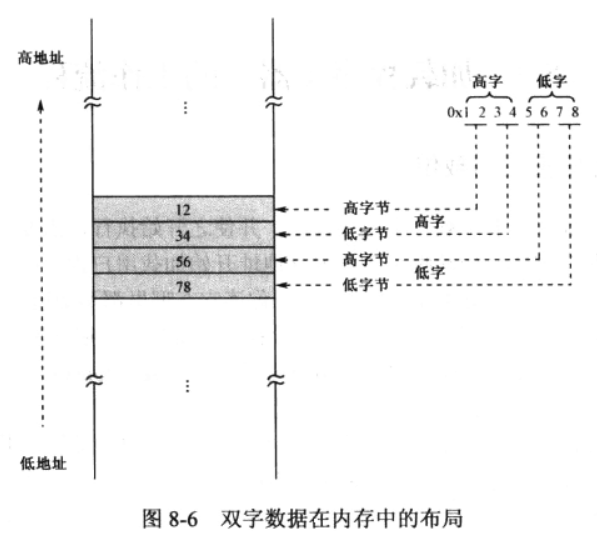
数据在内存中的布局
显示属性
属性字节:

例如,显示一个黑底白字的字母’A’,就要发送 0x4107。由于默认显示就是黑底白字,因此可以发送 0x41,但是必须把属性字节的位置空出来(即隔一个字节发送一个字符)。
逻辑地址与物理地址
IP 寄存器中,存储的是逻辑地址,需要配合 DS 寄存器确定最终的物理地址。
1 | mov ax,0b800h |
该段代码里,一开始设置了段寄存器 DS 的值为 0b800h
通过 jmp 指令来间接修改 IP,$$ 代表程序起始位置,$ 代表当前的地址。 jmp $ 是在当前打转转,不让程序直接退出。$-$$ 代表从程序起始到 jmp 的字节数,512 字节减去最后的 55 aa 两个字节的标志位为510,510-($-$$) 代表总共需要填充的 0 的个数。
位宽
某些情况下,我们需要指定位宽,例如立即数传送到内存
内存分段
16 位模式也称为实模式,当我们进入 32 位模式的时候会有一个保护模式。
8086CPU 的 IP 寄存器有 16 位,因此段的最大长度为 。这种情况下,总共有 16 个 64KB 的段。
那么段的最小长度是多少呢?答案是 16B,这种情况下,总共有 65536 个大小为 16B 的段。
Bochs 调试
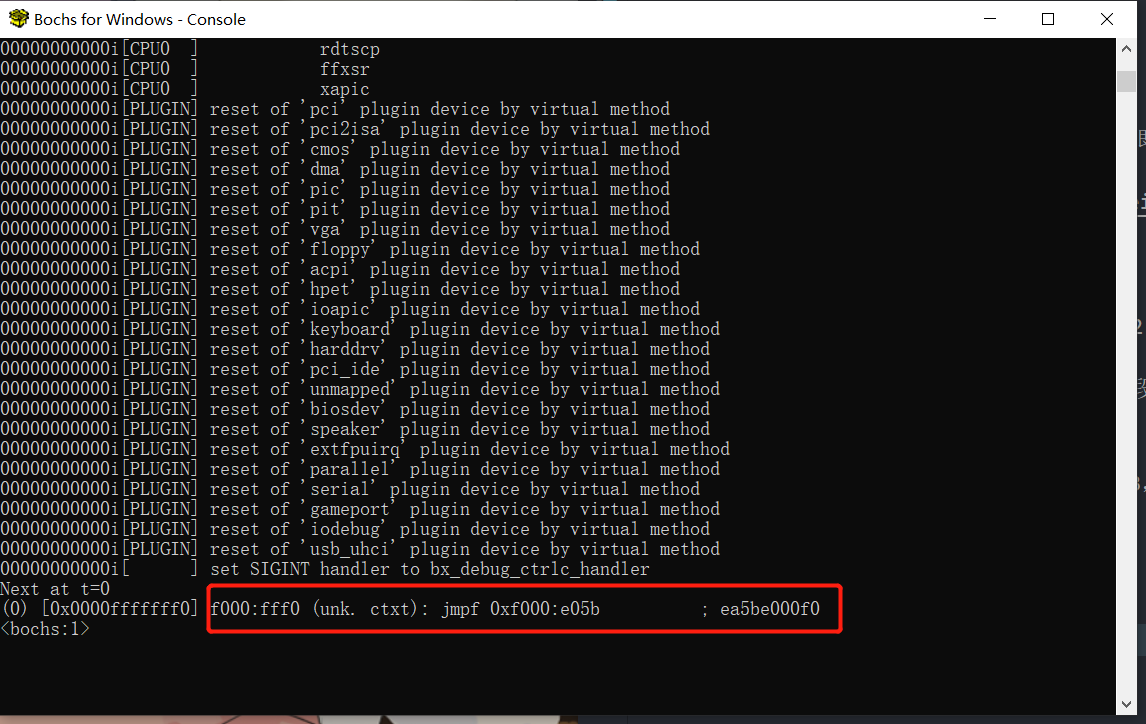
图中的第一条指令,即红框框起来的,是来自 ROM-BIOS 的指令。该指令跳转到地址 e05b。这个地址是 BIOS 程序的入口。
指令说明:
s,单步调试
b 0x7c00,打断点到内存某个位置
c,执行断点
r,查看寄存器
sreg,查看段寄存器
xp /nuf addr,查看物理内存,n=查看多少个单位,u=单位,u可以使b(字节),h(2字节),w(4字节),g(8字节),f=格式,f可以是 x(十六进制),d(十进制),u(无符号十进制),o(八进制),t(二进制),addr=地址
加减法指令

reg8 代表8位寄存器
imm16 代表16位的立即数
寄存器 eflags 的 CF 位,代表两个数相加、相减时产生的进位、借位。
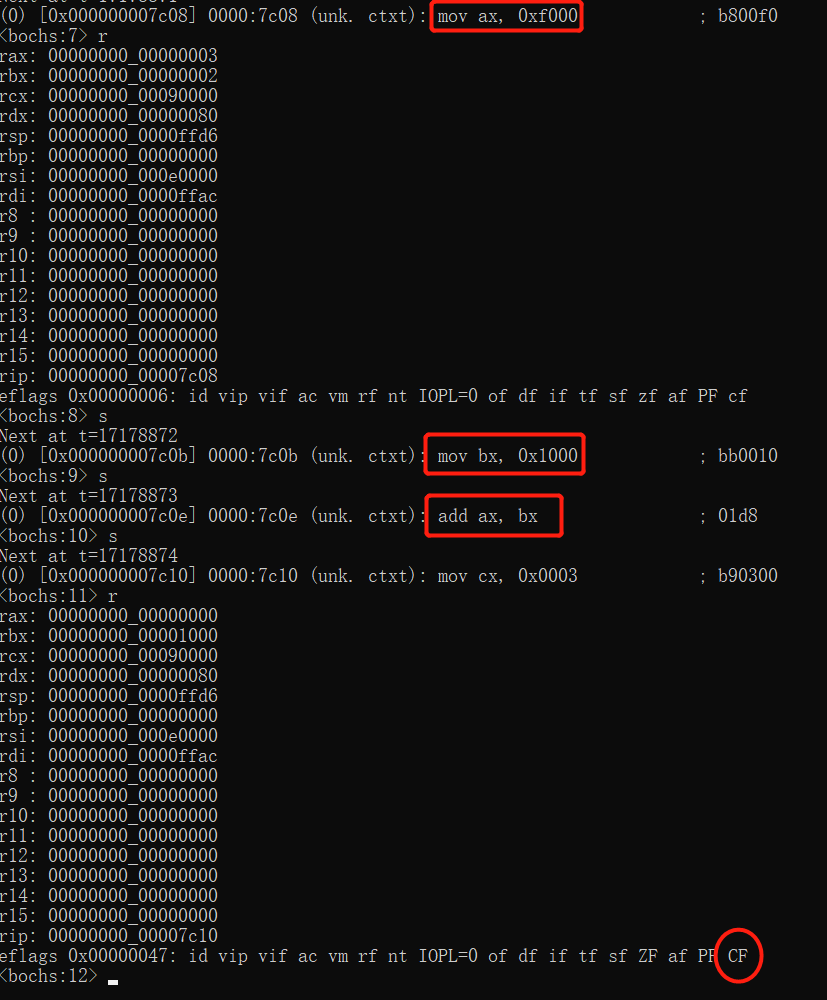
CF 是大写的,它就为1,小写的为0
inc 和 dec 是自增、自减的指令,但不影响 cf 的标志位。
在 16 位的 CPU 上做 32 位数的加减,需要使用2个新的指令 adc 和 sbb。
adc 在计算式额外增加 CF 的值,sbb 在计算时会额外减去 CF 的值。
乘除法指令
乘法的乘数需要实现放到 al 或者 ax 寄存器,被乘数跟在 mul 指令后面,即reg mul ax,计算结果放到 ax(8 位数乘法) 或者 ax:dx 寄存器(16 位数乘法,结果的高 16 位放到 dx,低 16 位放到 ax)

被除数需要先放到 ax 或者 dx:ax 寄存器,除数跟在 div 指令后面,即dx:ax div reg,商存在 al 寄存器,余数存在 ah 寄存器。

注意,mul 和 div 指令无法处理复数,而 add, sub, adc, sbb 指令剋应对有符号操作数。
在做 32 位除法的时候,例如
1 | mov dx,0x0008 |
会出现溢出的情况,造成死循环。我们可以自己写算法,用2个寄存器来保存出发的商,用1个寄存器来保存除法的余数。这里需要用到栈。可以将栈顶指针设置为0x0000,还记得在中的入栈和出栈的过程吗?入栈的时候,首先执行sp=sp-2,即sp=0x0000-2,为 0xfffe
32 位除法思路:被除数放在 dx:ax 里,除数放在 cx 里。除法做完后,商的高 16 位放在bx里,低 16 位放在 ax 里,余数放 dx 里。
1 | mov dx,0x0009 |
数学上可证明,第二次除法不会导致溢出。
汇编指令
标号
在 NASM 汇编语言里,每条指令的前面都可以拥有一个标号,以代表和指示该指令的汇编地址。
例如,infi: jmp near infi。这里带冒号的 infi 及是标号。 假如这条指令的汇编地址是 0x0000012B,那么 infi 就代表数值 0x0000012B,或者说是 0x0000012B 的符号化表示。
另外,标号之后的冒号也是可选的,所以下面的写法也正确 infi jmp near infi。标号并不是必需的,只有在我们需要引用某条指令的汇编地址时,才使用标号。正因如此,源程序中的绝大多数指令都没有标号。
标号可以单独占用一行的位置,像这样
1 | infi: |
标志寄存器的标志位

条件转移指令
当 ZF 标志位满足/不满足要求时执行:
jz jump if zero
jnz jump if not zero
cmp dest目的(reg/mem) source源(reg/mem/imm)
用于比较两个操作数,然后改变标志位的值
section 分段
nasm 中不再有 assume 操作,段地址完全取决于存入段寄存器的值。
section code align=16 vstart=0x7c00,section 后接名字,align设置内存对齐,vstart设置偏移地址
and/or/not/xor
and dest(reg/mem) source(reg/mem/imm),用来取特定某些位的值
or dest(reg/mem) source(reg/mem/imm),用来设置操作数某位的值
not reg/mem,用来取反
xor dest(reg/mem) source(reg/mem/imm),源和目的操作数都是同一个的话,可以将该操作数所有位置零
用户程序结构
一个规范的程序,应当包括代码段、数据点、附加段和栈段。这样一来,段的划分和段与段之间的界限在程序加载到内存之前就已经准备好了。
NASM 编译器使用汇编指令 SECTION 或 SEGMENT 来定义段。它的一般格式是
1 | SECTION 段名称 |
或
1 | SEGMENT 段名称 |
一旦定义段,后面的内容就都属于该段,除非又出现了另一个段的定义。有时候,程序并不以段定义语句开始。这种情况下,这些内容默认地自成一个段。
NASM 对段的数量没有限制,即,一些大的程序可能拥有不止一个代码段和数据段。
Intel 处理器要求段在内存中的起始物理地址起码是16字节对齐。汇编语言源程序中定义的各个段也有对齐方面的要求。具体做法是使用align=,用于指定某个 SECTION 的汇编地址对齐方式。
段的汇编地址是段内第一个元素(数据、指令)的汇编地址。为了方便取得该段的汇编地址,NASM 编译器提供了 section.段名称.start 来获取段地址。
伪指令 dd 用于声明和初始化一个双字,即一个32位的数据。
结合《X86汇编语言:从实模式到保护模式》的117-119页阅读下面的源码
硬盘读取
硬盘读取指令为 in/out
现在一般采用 LBA 方式,即逻辑块方式来读写硬盘。
in
从硬盘上读数据需要使用 in 指令,读到的数据会保存在寄存器中。由硬盘->寄存器。
in dest(al/ax) source(dx/imm8)
imm8 的最大值为255,而使用 dx 寄存器,则可以访问全部的 65535 个端口
1 | in ax,imm8 |
out
写入指令 out,目标是端口,由寄存器->硬盘
out dest(dx/imm8) source(al/ax)
例:
1 | out imm8,ax |
读取步骤
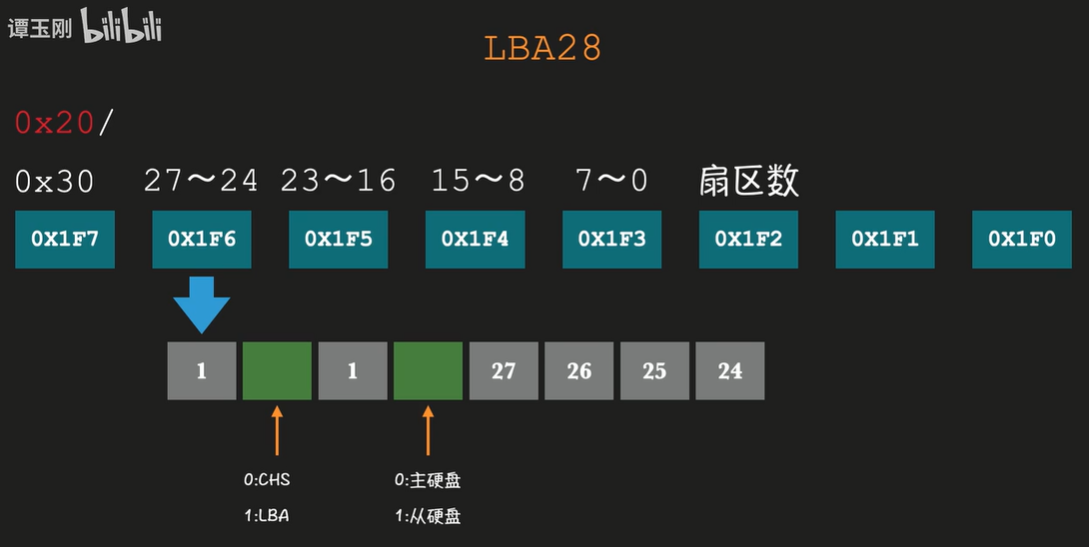
LBA28 模式下读取硬盘,有 8 个端口,从 0x1f0 ~ 0x1f7
-
首先要告诉硬盘读取几个扇区,该参数写入 0x1f2 中。
-
告诉硬盘从哪个逻辑扇区开始读。需要写入 28 位的逻辑扇区号,从 0x1f3 ~ 0x1f6;0x1f6 这个端口,只写入了逻辑扇区号的 24 ~ 27 位,剩下的 4 位要标识硬盘号和读写模式
-
向 0x1f7 端口写入 0x20 或 0x30,分别表示读硬盘和写硬盘
端口的含义如下图所示:
查看硬盘状态是否准备就绪,也是通过 0x1f7 端口查询。
只关心第 3 位和第 7 位,用 and 把其他位置零。

- 读取硬盘,0x1f0 是个 16 位的端口,一次可以读 2 个字节或者 1 个字。循环读取 0x1f0,把得到的数据保存到目标内存即可。
1 | readword: |

