| 发起:酱番梨 | 校对:唐里 | 审核:敬爱的勇哥 |
|---|---|---|
| 参与翻译(6)人:邓普斯•杰弗、liuxingbusi、路双宁、申请成为白菜、froginhot、阿阿飞 | ||
| 原文:Large-scale Graph Mining with Spark: Part 2 | ||
分为两部分的教程:
第1部分:无监督学习的图表。
第2部分(你现在正在这里!):你如何运用神奇的图形能力。 我们将讨论标签传播,Spark GraphFrames和结果。 GitHub上的这里有样本图和笔记本的项目:
在第1部分(这里),我们看到了如何用图解决无监督的机器学习问题,因为社区是集群。我们可以利用结点之间的边缘作为相似性或关系的指示器,就像在特征空间中距离用于度量其他类型的集群相似性一样。
在这里,我们深入了解社区检测的方法。我们构建并挖掘了一个大型的网络图,学习如何在Spark中实现一种称为标签传播算法(LPA)的社区检测方法。
通过标签传播检测社区
虽然有许多社区检测技术,但我只关注一种:标签传播。对于其他方法的概述,我推荐Santo Fortunato的“图中的社区检测”(Community Detection in Graphs)。
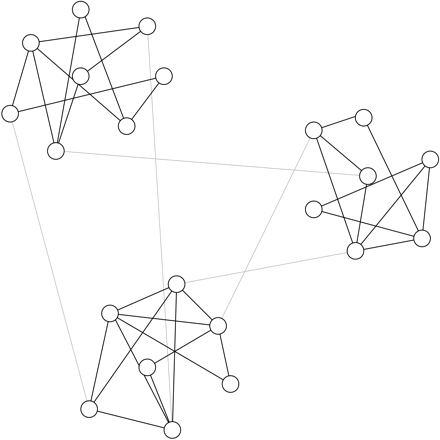
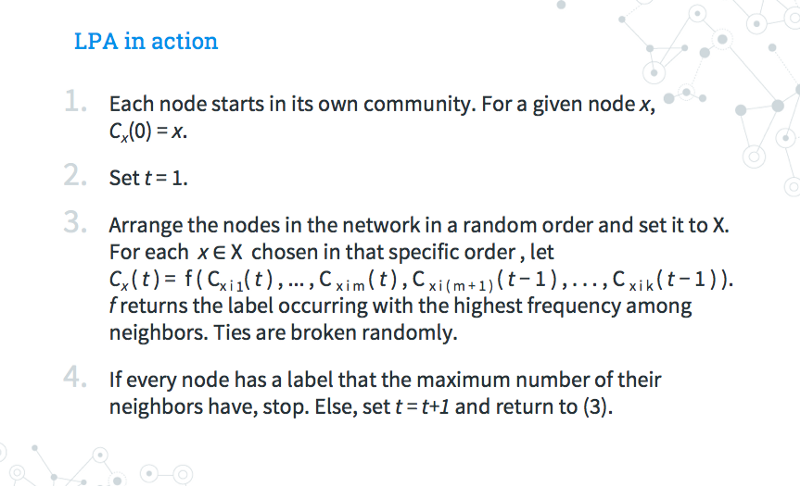
输入Raghavan、Albert和Kumara(2007)提出的标签传播算法(LPA)。LPA是一种迭代的社区检测解决方案,信息通过基于底层边缘结构的图“流动”。下面是LPA的工作原理:
-
在开始时,每个结点都从自己的社区开始。
-
每次迭代,随机遍历所有结点。对于每个结点,通过使用其大多数邻近点的标签来更新该结点的社区标签。随机打破任何联系。
-
如果所有结点都使用其邻近的多数标签进行标记,则该算法已达到停止准则。如果没有,重复步骤 2。
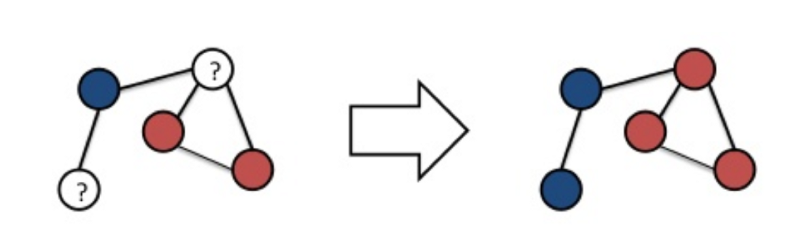
标签传播直观上来说是有意义的。假设有一天在工作中,有人得了感冒,并 “传播” 这种疾病,直到你工作场所的每个人都和他们附近的人一样生病。与此同时,街对面 Foobar公司的员工感染并传播了流感。你和 Foobar 公司之间没有太多的联系,所以当每个社区的成员都染上了这种疾病时,“传播” 就停止了。达到收敛了!不过,抽泣和头痛,实在是太糟糕了。
为什么使用LPA?
-
带标签的数据很好,但不是必需的。这使得 LPA 适合于我们的无监督机器学习用例。
-
参数调优很简单。LPA 使用最大迭代参数运行,并且使用默认值 5 就可以得到一些好的结果。Raghavan 和她的合作者在几个有标签的网络上测试了 LPA。他们发现至少 95% 的结点在 5 次迭代中被正确分类。
-
一个先验的集群数量,集群大小,其他指标不需要。如果您不想假设您的图具有特定的结构或层次结构,那么这一点非常重要。对于网络图的网络结构、拥有数据的社区数量或社区的预期大小,不需要任何先验的假设。
-
运行时间内近线性。LPA 的每次迭代都是 O (m),边的数量是线性的。与 以前的一些社区检测解决方案中的O (n log n) 或 O (m+n) 相比,整个步骤序列的运行时间几乎是线性的。
-
可解释性。当有人问起时,您可以解释为什么将结点分组到某个社区中。
工具的选择
首先,我们快速但不详尽地分析一下这些工具。我根据图的规模,库是否适合Python和生成简单可视化的容易程度来划分这些工具。
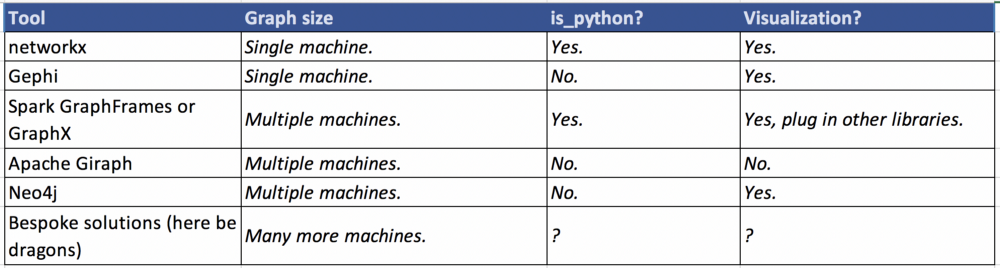
一个不详尽的工具菜单:
-
对于适合单个机器的数据,Python的networkx包在图探索上易于使用,是个好的选择。它实现了大多数常见的算法(包括标签传播,PageRank,最大团算法等等)。它也可以做简单的可视化。
-
Gephi 是一个开放的图分析工具。它不是Python的一个包,而是拥有有健壮的UI和令人印象深刻的图形可视化功能的独立工具。如果你在 处理较小的图,需要强大的可视化,喜欢使用UI而不是Python,那么试试Gephi吧。
-
Spark有两个图形库,分别是GraphX和GraphFrames。当你的图形数据太大难以安装在一台机器上(受限于分配给Spark应用程序的资源数量),希望利用并行处理和Spark的一些内置容错功能时,Spark是一个极佳的解决方案。Pyspark是Spark的Python API,非常适合集成到其他库中,比如scikit-learn、matplotlib或networkx。
-
Apache Giraph是Pregel的一个开源实现,Pregel是由Googl创建的图形处理架构。相比之前的解决方案,Giraph的门槛更高。但是Giraph 对大规模图形的分析部署能力很强。我选择了更轻量级的东西,它同时具有Scala和Python的API。
-
Neo4j 是一个图形数据库系统。它有Python的客户端,但是你需要再单独安装Neo4j。由于我的分析只是一个POC,所以我想避免维护和部署一个与现有代码不集成的完全独立的工具。
-
最后,理论上你可以实现自己的解决方案。但在最初探索数据科学时,我并不鼓励这样做。许多定制的图挖掘算法都是针对非常特定的用例(例如,只在图聚类方面非常高效,其他方面并非如此)。如果你确实需要处理非常非常大的数据集,那么首先考虑对你的图进行抽样,过滤感兴趣的子图,从示例中推断关系,基本上可以从现有工具中获得更多的好处。
考虑到我正在处理的数据大小,我选择了Spark GraphFrames。
记住:项目的最佳图形库取决于语言、图形大小、存储图形数据的方式和个人偏好!
构建通用网络图形爬虫
太好了!我深信图是多么的棒,它们是有史以来最酷的东西!那我如何开始在真实的数据上使用社区检测呢?
步骤
-
获取数据:Common Crawl数据集是一个开放的网络爬虫库,非常适合做网络图形的研究。抓取结果以WARC(网络箭头)的格式存储。除页面以外,数据集还包含爬取日期、使用的头信息和其他元数据。
我从2017年9月的crawl上采集了100个文件。文件
warc.path.gz包含路径名;使用这些路径,从步骤3上下载相应的文件。 -
分析和清理数据:首先,我们需要每个页面的HTML内容。对每个页面,我们收集URL和链接到其它页面的URL来创建图。
为了从原始的WRC文件中提取边信息,我写了一些清洗数据的代码,这些代码可能永远不会被公开。至少它完成了工作,所以我可以专注更有趣的事!我的解析代码是用Scala编写的,但是我的demo是用pysprk完成的。我用了WarcReaderFactory和Jericho parser库。对python来说,像warc这样的库基本可以满足你对数据分析的要求了。
在我获得了全部html内容所指向的
href链接后,-
我根据域名来绘制边界,而不是根据完整的URL。例如,
medium.com/foo/bar和medium.com/foobar,我只创建了一个medium.com结点,它获取了与其他域之间的链接关系。 -
我过滤掉了循环。循环是那些链接到自己的结点的边,对我的目标无用。如果
medium.com/foobar链接到同一个域medium.com/placeholderpage,则不会绘制边。 -
我移除了很多受欢迎的资源链接,包括流行的CDN,trackers和assets。对于我的初步探索,我只想关注那些人们可能去访问的网页。
-
-
初始化Spark Context:对于那些在家中关注的人,请参见GitHub上的demo。此demo只在本地计算机上运行。你不会获得分布式集群的所有计算资源,但你将了解如何开始使用Spark GraphFrames。
我将使用Spark 2.3。引入
pyspark和其它所需的库,包括graphframes。然后创建SparkContext,这将允许你运行一个pyspark application。
1 | # add GraphFrames package to spark-submit |
- 创建一个GraphFrame:一旦你获得了清理后的数据,就可以把顶点和边加入到Spark DataFrame中。
-
顶点包含每个结点的
id和结点的name,name用域名来表示。 -
边是有向边,从源域
src到链接域dst。
-
1 | # show 10 nodes |
接下来你可以用顶点和边创建GraphFrame对象。瞧!你得到了一个图!
1 | # create GraphFrame |
- 运行LPA:你只用一行代码即可运行LPA。这里,我运行LPA时用了5次迭代(
maxIter)。
1 | # run LPA with 5 iterations |
运行graph.labelPropagation(),返回一个带有结点的DataFrame和一个label,label表示该结点属于哪个社区。你可以使用label来了解社区大小的分布并放大感兴趣的区域。例如,要发现与pokemoncentral.it在同一社区中的每个其他网站(老实说,谁不会?),过滤所有其它label = 1511828488194的结点。
结果
当我在我的样本Common Crawl网络图上运行LPA时发生了什么?

-
我的原始数据中有超过1500万个网站。这是很多结点,其中许多包含冗余信息。我描述的清洗过程将图转化为更少,更有意义的边缘。
-
LPA发现了超过4,700个社区。但是,这些社区中有一半以上只包含一个或两个结点。
-
在规模范围的另一端,最大的社区是超过3,500个不同的网站!为了给出范围的概念,这是在我最终的graph post-filtering中的大约5%的结点
社区规模的极端情况说明了LPA的一个缺点。收敛太多,可能存在太大的集群(由某些标签主导密集连接的网络引起)。收敛太少,你可能会得到更多,更小的社区,这些社区不那么有用。我发现最有趣的集群最终介于两个极端(收敛太多和收敛太少)之间。
融合和小世界的网络效应
在我的数据集中,大约5次迭代后 LPA确实收敛了。您可以看到社区数量达到约4,700。 Raghavan和她的同事也用他们的标记图显示了这个属性。
一种解释小世界网络效应的可能机制——图形聚类的趋势,但相比于结点数量也具有较短的路径长度。换句话说,虽然图有集群,但你也希望能够在5-6次跳跃之内,实现从你的网络中的一个朋友到另一个朋友。许多真实世界的图,包括互联网和社交网络,共享这个属性。您可能也知道这是六度分离现象。
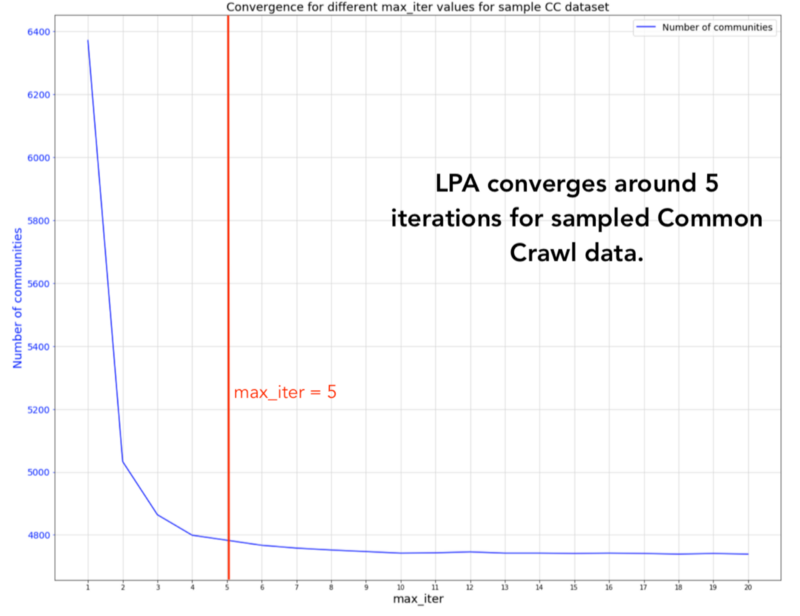
5次迭代后,社区数量趋于平稳。
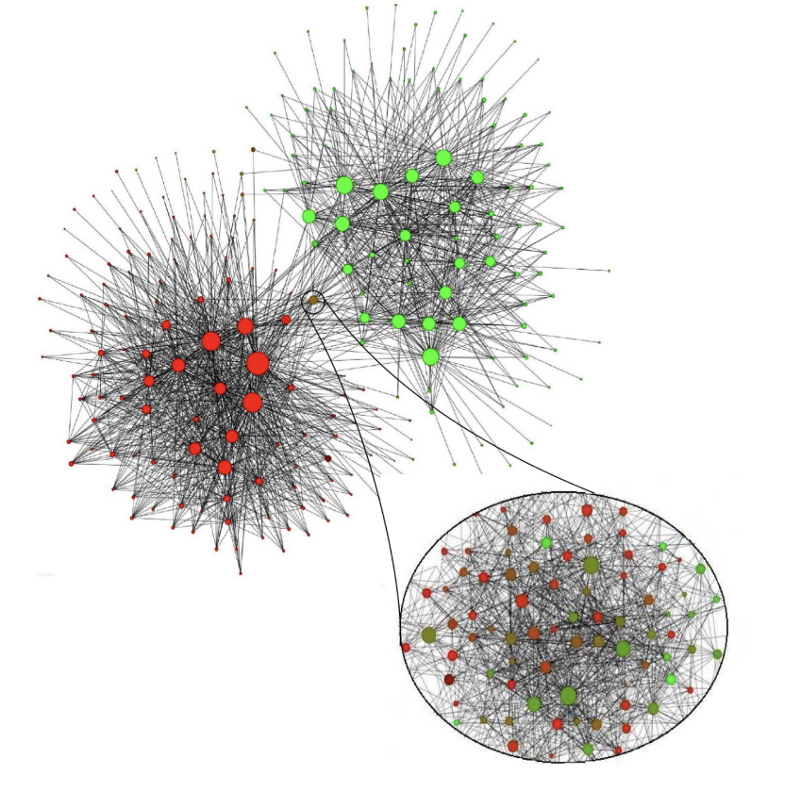
样本集群
在粗略的层面上,让我们看一些样本集群。与传统的无监督聚类一样,社区可以是不同站点的混合,尽管有一些我们在没有LPA的情况下不会发现的感兴趣的主题!从左到右:
-
电子学习网站:与电子学习页面相关或链接的网站。是时候找一些新的数据科学MOOC了!
-
Bedbug网站:与房地产和bugs有关的网站。所有这些网站使用相同的模板/图像,只是略有不同的域名。不要以为我已经到底了。
-
星球大战社区:谈论星球大战电影,活动和纪念品的网站经常相互链接。

值得强调的是,我们在没有文本处理和功能选择,手动标记,域名功能,甚至不知道要查找多少社区的情况下, 获得了这些集群。我们通过利用网络图的底层网络结构找到了感兴趣的社区!
下一步
我只是触及了网络图社区的表面。未来的研究可能会有很多方向可以实现。例如:
-
层和元数据传播:如果我们添加信息,比如边的权重,链接类型,或外部的标签数据,我们如何通过图传播这个信息?
-
删除/添加结点 和度量社区上的影响:我很好奇如何添加或去除高边缘中心结点改变LPA的有效性和社区结果的质量。
-
观察web图随着时间的演化:每个月都有一个新Common Crawl数据集!将会是很有趣的看到什么群蔟随着时间的推移出现。相反,哪些社区保持不变?我们知道,互联网不是静态的。
这个Github仓库(repo)的演示包含一个10k结点小的web图例子。 这儿也有一份在Docker安装设置并且在运行在pyspark notbooks上的说明。
我希望这将有助于快速实现web图数据实验和为你自己的数据科学问题来学Spark GraphFrames。
Happy exploring!
致谢
感谢Yana Volkovich博士深入学习图论并成为一名伟大的导师。还要感谢我的其他同事,他们对我的演讲给予了反馈。
参考文献
-
Adamic, Lada A., and Natalie Glance. “The political blogosphere and the 2004 US election: divided they blog.” Proceedings of the 3rd international workshop on Link discovery. ACM, 2005.
-
Common Crawl dataset (September 2017).
-
Farine, Damien R., et al. “Both nearest neighbours and long-term affiliates predict individual locations during collective movement in wild baboons.” Scientific reports 6 (2016): 27704
-
Fortunato, Santo. “Community detection in graphs.” Physics reports 486.3–5 (2010): 75–174.
-
Girvan, Michelle, and Mark EJ Newman. “Community structure in social and biological networks.” Proceedings of the national academy of sciences 99.12 (2002): 7821–7826.
-
Leskovec, Jure, Anand Rajaraman, and Jeffrey David Ullman. Mining of massive datasets. Cambridge University Press, 2014.
-
Raghavan, Usha Nandini, Réka Albert, and Soundar Kumara. “Near linear time algorithm to detect community structures in large-scale networks.” Physical review E 76.3 (2007): 036106.
-
Zachary karate club network dataset — KONECT, April 2017.

