数据集划分:
含义:
训练集:用训练集对算法或模型进行训练;
验证集:利用验证集进行交叉验证,即评估几种算法或模型中哪一个最好,从而选择出最好的模型;
测试集:最后利用测试集对模型进行测试,获取模型运行的无偏估计。
在VOC数据集中,包含4种数据文件,train、test、val、trainval
train.txt:用于训练的图片数据名称;
test.txt:用于测试的图片数据名称;
val.txt:用于验证的图片数据名称;
trainval.txt:train+val数据集和。
划分:
在小数据量的时代,如 100、1000、10000 的数据量大小,可以将数据集按照以下比例进行划分:
- 无验证集的情况:70% / 30%;
- 有验证集的情况:60% / 20% / 20%;
数据集格式
训练时常用的数据集格式有
- VOC
- COCO
标准的VOC数据格式如下:
- VOC2007/
- Annotations/
- 000000.xml
- 000001.xml
- …
- ImageSets/
- Main/
- train.txt
- test.txt
- val.txt
- trainval.txt
- Main/
- JPEGImages/
- 000000.jpg
- 000001.jpg
- …
- Annotations/
标准的coco数据集格式如下:
- COCO/
- annotations/
- instances_train2017.json
- instances_val2017.json
- images/
- train2017/
- 000000.jpg
- 000001.jpg
- …
- val2017/
- 000007.jpg
- 000012.jpg
- train2017/
- annotations/
数据集标注工具
labelme
labelme官方提供了一些格式转换的工具,见
另外,目标检测系列一:如何制作数据集?的github里也提供了labelme转化为coco,voc格式的python代码。
mAP
mAP,其中代表P(Precision)精确率。AP(Average precision)单类标签平均(各个召回率中最大精确率的平均数)的精确率,mAP(Mean Average Precision)所有类标签的平均精确率。
IoU(交并比)
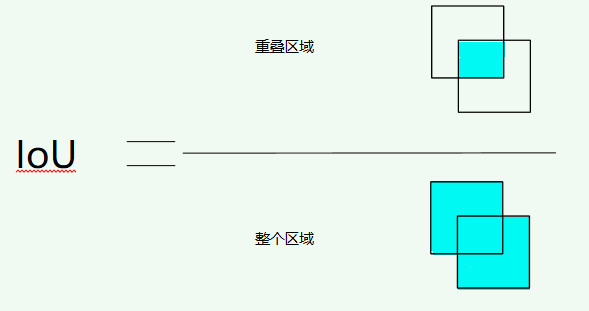
IoU表示了产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率或者说重叠度,也就是它们的交集与并集的比值。相关度越高该值。最理想情况是完全重叠,即比值为1。
计算公式:
正样本,负样本
参考faster以及SSD两种检测框架中对于正负样本的选取准则,首先,检测问题中的正负样本并非人工标注的那些框框,而是程序中(网络)生成出来的ROI,也就是faster rcnn中的anchor boxes以及SSD中在不同分辨率的feature map中的默认框,这些框中的一部分被选为正样本,一部分被选为负样本。另外一部分被当作背景或者不参与运算。不同的框架有不同的策略,大致都是根据IOU的值,选取个阈值范围进行判定,在训练的过程中还需要注意均衡正负样本之间的比例。在fast的框架中,也是需要多SS算法生成的框框与GT框进行IOU的判断,进而选取正负样本,总之,正负样本都是针对于程序生成的框框而言,而非GT数据。
选取的正负样本是用来训练回归损失或者分类损失的。
正例与负例
True positives(TP):被正确地划分为正样本的个数。即实际为正样本且被分类器划分为正样本的实例数(被分为正样本,并且分对了);
False positives(FP):被错误地划分为正样本的个数。即实际为负样本但被分类器划分为正样本的实例数(被分为正样本,但是分错了);
False negatives(FN):被错误地划分为负样本的个数,即实际为正样本但被分类器划分为负样本的实例数(被分为负样本,但是分错了);
True negatives(TN):被正确地划分为负样本的个数,即实际为负样本且被分类器划分为负样本的实例数(被分为负样本,而且分对了)。
准确率(精度)(accuracy), 精确率(查准率)(precision), 召回率(查全率)(recall)
accuracy:分类错误的样本数占样本总数的比例称为错误率(error rate),如果在m个样本中有a个样本分类错误,则错误率;相应的,成为“精度(accuracy)”
precision:
recall:
一般来说,召回率越高,准确率越低。
举例
假设我们在做一个识别猫咪的模型,测试集中包含100个样本,其中猫咪60张,小狗40张。现在模型的结果显示,猫咪一共有52张(也就是说52张被模型标记为正例,剩余的48张被模型标记为负例),其中确实为猫咪的有50张(TP=50, FP=2),也就是还有10张猫咪没有被检测出来(也就是说48张负例里边有10张是猫咪)(TN=38,FN=10)
指标如下:
改动一
现在我们改一下这个例子,目的是为了深入体会下这几个指标的含义。
假设我们在做一个识别猫咪的模型,测试集中包含100个样本,其中猫咪60张,小狗40张。现在模型的结果显示,猫咪一共有20张(也就是说20张被模型标记为正例,剩余的80张被模型标记为负例),其中确实为猫咪的有20张(TP=20, FP=0),也就是还有40张猫咪没有被检测出来(也就是说80张负例里边有40张是猫咪)(TN=40,FN=40)
指标如下:
改动二
假设我们在做一个识别猫咪的模型,测试集中包含100个样本,其中猫咪60张,小狗40张。现在模型的结果显示,猫咪一共有70张(也就是说70张被模型标记为正例,剩余的30张被模型标记为负例),其中确实为猫咪的有60张(TP=60, FP=10),也就是还有0张猫咪没有被检测出来(也就是说30张负例里边有0张是猫咪)(TN=30,FN=0)
为什么要引入recall和precision?
recall和precision是模型性能两个不同维度的度量:在图像分类任务中,虽然很多时候考察的是accuracy,比如ImageNet的评价标准。
但具体到单个类别,如果recall比较高,但precision较低,比如大部分的汽车都被识别出来了,但把很多卡车也误识别为了汽车,这时候对应一个原因。如果recall较低,precision较高,比如检测出的飞机结果很准确,但是有很多的飞机没有被识别出来,这时候又有一个原因。
recall度量的是「查全率」,所有的正样本是不是都被检测出来了。比如在肿瘤预测场景中,要求模型有更高的recall,不能放过每一个肿瘤。
precision度量的是「查准率」,在所有检测出的正样本中是不是实际都为正样本。比如在垃圾邮件判断等场景中,要求有更高的precision,确保放到回收站的都是垃圾邮件。
相爱相杀
在深度学习中,精确率(Precision)和召回率(Recall)是常用的评价模型性能的指标,从公式上看两者并没有太大的关系,但是实际中两者是相互制约的。我们都希望模型的精确了和召回率都很高,但是当精确率高的时候,召回率往往较低;召回率较高的时候精确率往往较低。
如何协调Precision和Recall?
F度量
比如在一般的搜索任务时,在保证召回率的同时,尽量提高精确率;
在癌症检测、金融诈骗任务时,在保证精确率的同时,尽量提高召回率。
很多时候,我们需要综合权衡这2个指标,这就引出了一个新的指标F-Score,这是综合考虑Precision和Recall的调和值
当时,称为,这时recall和precision都很重要,权重相当。当有些情况下我们认为精确率更重要,那就要调整的值小于1,如果我们认为召回率更加重要,那就调整的值大于1,比如。
AP
除了用F值来衡量外,还可以用平均精度(Average Precision, AP)——以recall和precision为横、纵坐标,得到二维曲线,即PR曲线。将PR曲线下的面积当作衡量尺度,得到AP值。
这个计算的过程和相关图全部来自上面的知乎回答:
假设我们有7张图片(Images1-Image7),这些图片有15个目标(绿色的框,即人工标注的框,GT的数量,all ground truths)以及24个预测边框(红色的框,模型生成的,A-Y 编号表示,并且有一个置信度值)
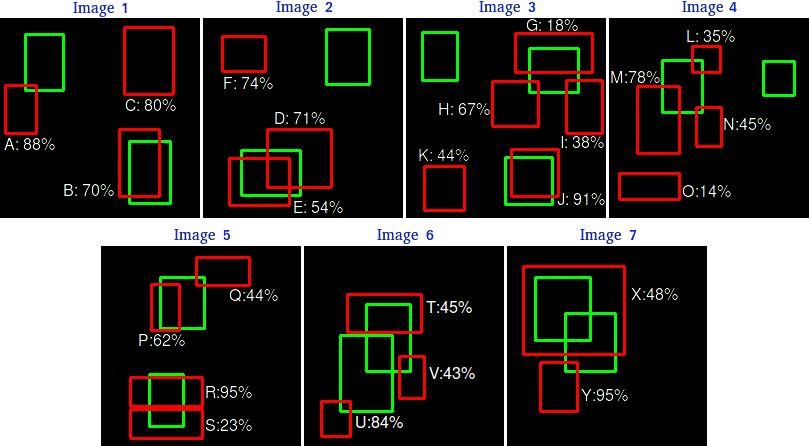
根据上图以及说明,我们可以列出以下表格,其中Images代表图片的编号,Detections代表预测边框的编号,Confidences代表预测边框的置信度,TP or FP 代表预测的边框是标记为TP还是FP(认为预测边框与GT的IOU值大于等于0.3 就标记为TP;若一个GT有多个预测边框,则认为IOU最大且大于等于0.3的预测框标记为TP,其他的标记为FP,即一个GT只能有一个预测框标记为TP),这里的0.3是随机取的一个值。

通过上表,我们可以绘制出P-R曲线(因为AP就是P-R曲线下面的面积),但是在此之前我们需要计算出P-R曲线上各个点的坐标,根据置信度从大到小排序所有的预测框,然后就可以计算Precision和 Recall的值,见下表。(需要记住一个叫累加的概念,就是下图的ACC TP和ACC FP)
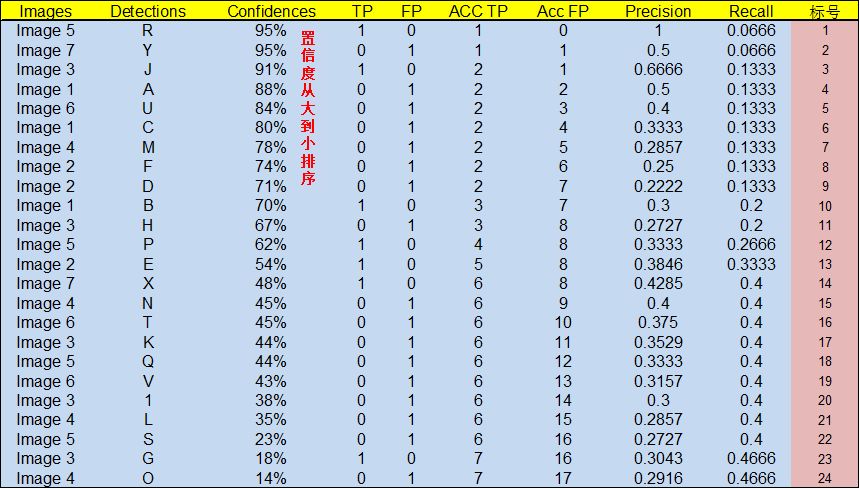
- 标号为 1 的 Precision 和 Recall 的计算方式:
(all ground truths上面有定义过了)
- 标号 2:
- 标号 3:
- 其他的依次类推
ps:这些标号里面用于计算的TP,FP,都是“ACC TP”和“ACC FP”
然后就可以绘制出 P-R 曲线
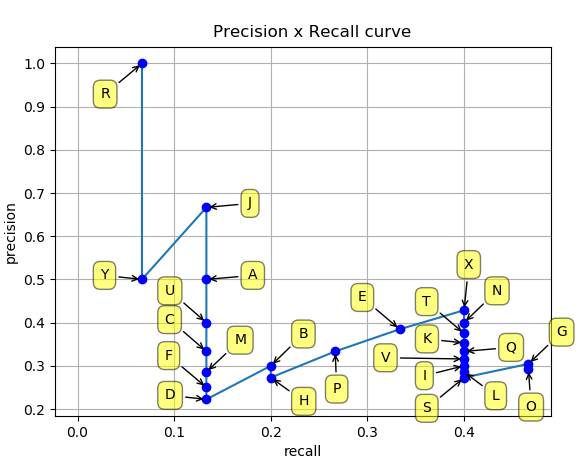
得到 P-R 曲线就可以计算 AP(P-R 曲线下的面积),要计算 P-R 下方的面积,一般使用的是插值的方法,取 11 个点 [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1] 的插值所得
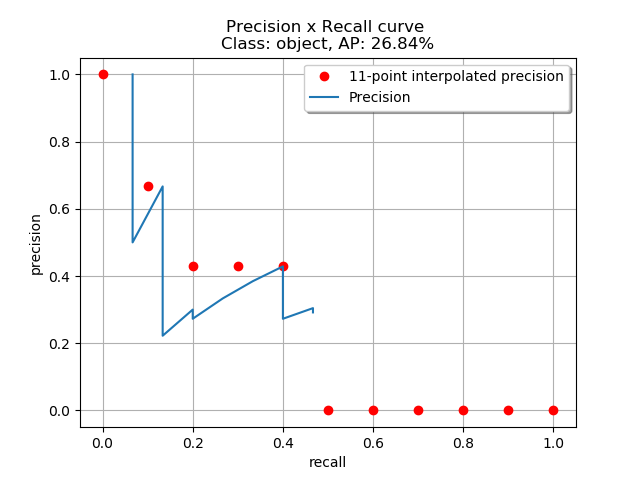
得到一个类别的 AP 结果如下:
mAP
mAP即平均AP值,是对多个验证集求平均AP值,其中指验证集的个数。
NMS(非极大抑制)
用于去除冗余的检测框
- 假设3个框,根据SVM的打分排序,概率从大到小为A、B、C
- 判断B、C与A的重复率 IoU 是否大于阈值,如果大于,扔掉,如果小于,保留
- 保留下来的框,根据打分顺序,重复上述过程
速度
除了检测准确度,目标检测算法的另外一个重要性能指标是速度,只有速度快,才能实现实时检测,这对一些应用场景极其重要。评估速度的常用指标是每秒帧率(Frame Per Second,FPS),即每秒内可以处理的图片数量。
未完待续

